#9. 복합 인덱스 심화
옵티마이저는 왜 그 인덱스를 골랐을까
# 복합 인덱스 심화 — 옵티마이저는 왜 그 인덱스를 골랐을까
> 📘 **학습자료 10편 / 11편** | 연결 퀴즈: [**인덱스 응용1 풀러가기**](quiz.html?set=E)
> 9편까지 인덱스의 구조와 활용을 다뤘다면, 이번 편은 **"같은 쿼리에 후보 인덱스가 여럿일 때 옵티마이저가 무엇을 보는가"** 입니다.
> 인덱스 설계가 끝난 뒤, 실제 운영에서 쿼리를 진단할 때 가장 자주 마주치는 장면입니다.
> 📚 **이전 편**: [9편 - 커버링 인덱스]
> 9편에서 본 "두 번 탐색 vs 한 번 탐색"의 차이가 이번 편의 한 챕터를 통째로 끌고 갑니다.
> EXPLAIN의 `Extra`가 익숙하지 않다면 9편을 먼저 보고 오세요.
## 이 자료를 다 읽으면 알게 되는 것
- **PK 길이**가 보조 인덱스 전체 성능에 미치는 영향
- 같은 쿼리에 후보 인덱스가 여럿일 때, 옵티마이저가 **어떻게 고르는지**
- EXPLAIN의 **`rows`, `filtered`, `Extra`** 를 읽고 옵티마이저의 판단을 추적하는 법
- 같은 인덱스를 써도 어떤 쿼리는 빠르고 어떤 쿼리는 느린 이유
---
## 📑 목차
- [1. 복합 인덱스는 "정렬된 사전"](#1-복합-인덱스는-정렬된-사전)
- [2. PK는 왜 짧게 만들라고 할까](#2-pk는-왜-짧게-만들라고-할까)
- [⭐ 3. 옵티마이저는 왜 그 인덱스를 골랐을까](#3-옵티마이저는-왜-그-인덱스를-골랐을까)
- [4. 같은 인덱스를 써도 왜 느릴 수 있을까](#4-같은-인덱스를-써도-왜-느릴-수-있을까)
- [핵심 요약](#핵심-요약)
---
## 1. 복합 인덱스는 "정렬된 사전"
본격적으로 들어가기 전에, 이 편 전체를 끌고 갈 비유를 깔아둡니다.
복합 인덱스 `(A, B, C)`를 떠올리는 가장 쉬운 방법은 **국어사전**입니다.
- 1순위로 첫 글자(A)가 가나다순 정렬
- 1순위가 같으면 두 번째 글자(B)로 정렬
- 그것도 같으면 세 번째 글자(C)로 정렬
"가" 항목을 펼치면 그 안에 "가, 각, 간, 갇…"이 또 정렬되어 있고, "각" 안에 다시 "각각, 각도, 각오…"가 정렬된 구조죠. 이 사전은 **앞에서부터 차례로 따라갈 때만** 쓸모가 있습니다. 가운데 글자만으로 단어를 찾으려 하면 사전 전체를 뒤져야 합니다.
> 이번 편에서는 그 위에서 **"옵티마이저가 어떤 사전을 펼칠지 어떻게 고르는가"** 를 다룹니다.
---
## 2. PK는 왜 짧게 만들라고 할까
InnoDB에서 PK는 단순한 "행 식별자"가 아닙니다. **클러스터링 인덱스의 키**이자, **모든 보조 인덱스가 내부적으로 들고 다니는 값**입니다.
3편과 9편에서 본 보조 인덱스 리프 노드의 구조를 다시 떠올려봅시다.
> **보조 인덱스 키 + 클러스터링 인덱스 키(PK)**
`(first_name, gender)` 보조 인덱스의 리프 노드에는 다음이 들어 있습니다.
| 인덱스 컬럼값 | PK 값 |
|---|---|
| ('Ebbe', 'F') | 10001 |
| ('Ebbe', 'M') | 10042 |
| ('Ebbe', 'M') | 10089 |
| ... | ... |
### PK가 길어지면 무슨 일이 일어나나
PK가 `BIGINT(8 byte)`인 경우와 `VARCHAR(64) UTF8`인 경우를 비교해보면:
| PK 타입 | PK 1개당 크기 | 보조 인덱스 항목 1개당 추가 부담 |
|---|---|---|
| BIGINT | 8 byte | 8 byte |
| VARCHAR(64) UTF8 | 최대 192 byte | 최대 192 byte |
행이 1,000만 건이고 보조 인덱스가 N개라면, 단순 계산만으로도 **수 GB × N의 차이**가 납니다.
이게 왜 문제냐 하면:
- 보조 인덱스 한 페이지(보통 16KB)에 들어가는 항목 수가 줄어듭니다
- 같은 범위를 읽는 데 더 많은 페이지를 읽어야 합니다
- 버퍼풀에 캐시할 수 있는 인덱스 양이 줄어듭니다
> ⚠️ **주의할 부분**
> 클러스터링 인덱스 자체는 PK 1개만 키로 갖습니다. PK가 길어서 영향을 받는 건 **보조 인덱스 N개 전부** 입니다.
> 보조 인덱스가 많은 테이블일수록 PK 길이의 영향이 커집니다.
### 정리 — PK 설계 원칙
- **NOT NULL**: PK는 null을 허용하지 않습니다
- **짧게**: 모든 보조 인덱스가 들고 다닐 값이라서
- **변하지 않는 값**: PK가 바뀌면 모든 보조 인덱스의 꼬리표를 다 바꿔야 합니다
> 💡 **MySQL 공식 문서의 표현**
> "PK가 길면 보조 인덱스가 더 많은 공간을 사용한다. 그러므로 짧은 PK를 두는 것이 유리하다."
---
## 3. 옵티마이저는 왜 그 인덱스를 골랐을까
> ⭐ **이 자료에서 가장 중요한 섹션입니다.** 같은 쿼리에 후보 인덱스가 여럿 있을 때 옵티마이저의 판단 기준을 추적하는 법입니다.
### 상황 설정
`employees` 테이블에 두 개의 인덱스가 있습니다.
- `idx_date_name_gender_pk`: `(birth_date, first_name, gender, emp_no)`
- `idx_name_gender_pk`: `(first_name, gender, emp_no)`
다음 쿼리를 실행합니다.
```sql
SELECT *
FROM employees
WHERE birth_date BETWEEN '1953-05-30' AND '1954-05-31'
AND first_name = 'Ebbe'
AND gender = 'F'
GROUP BY emp_no;
```
이 쿼리는 두 인덱스 모두 후보입니다. 그런데 옵티마이저는 **`idx_name_gender_pk`** 를 고릅니다. 왜일까요?
### 핵심 비유: "사전을 어디서 펼칠 것인가"
사전을 펼친다고 생각해보세요.
**시나리오 A — `idx_date_name_gender_pk` 사용**
> "1953-05-30부터 1954-05-31 사이의 어느 날에 태어난 사람을 다 펼쳐놓고, 그 안에서 'Ebbe'이고 'F'인 사람을 찾아라"
생일이 **범위 조건**이라서 사전을 한 군데서 펼치는 게 아니라 **약 1년치 페이지를 통째로 훑어야** 합니다. 그러면서 그 안에서 이름과 성별을 다시 골라내야 합니다.
**시나리오 B — `idx_name_gender_pk` 사용**
> "이름이 'Ebbe'이고 성별이 'F'인 사람을 사전에서 콕 찍어라. 그다음 그 사람들 중 1953-05-30 ~ 1954-05-31 생인 사람만 남겨라"
이름과 성별 둘 다 **동등 조건**이라 사전을 딱 한 지점에서 펼칠 수 있습니다. 거기서 나온 후보가 적다면, 그 안에서 생일을 검사하는 건 금방이죠.
### EXPLAIN으로 옵티마이저의 판단 추적하기
옵티마이저의 판단 근거는 EXPLAIN의 `rows`와 `filtered` 컬럼에 그대로 드러납니다.
| 컬럼 | 의미 |
|---|---|
| `rows` | 인덱스를 통해 읽을 것으로 예측되는 행 수 |
| `filtered` | 그 행들 중 실제 조건에 맞을 것으로 예측되는 비율(%) |
두 인덱스를 강제로 각각 사용해서 비교하면:
| 인덱스 | rows | filtered |
|---|---|---|
| `idx_name_gender_pk` | 79 | 14.15 |
| `idx_date_name_gender_pk` | 42,560 | 5 |
차이가 압도적입니다. 동등 조건을 우선 활용한 쪽은 후보가 79개에 불과한데, 범위 조건을 앞세운 쪽은 4만 건이 넘습니다. 옵티마이저는 당연히 비용이 적은 쪽을 고릅니다.
> 💡 **rows × filtered가 옵티마이저 판단의 핵심 지표**
> 둘을 곱한 값이 "이 인덱스로 처리 후 실제로 남을 행 수"의 추정치입니다.
> 위 예시: 79 × 14.15% ≈ 11행 vs 42,560 × 5% ≈ 2,128행. 약 200배 차이.
### 한 줄 결론
> 🎯 **복합 인덱스는 동등 조건을 앞에, 범위 조건을 뒤에 두어야 효율적이다.**
> 인덱스를 설계할 때도, 쿼리를 짤 때도 이 원칙을 의식하세요.
---
## 4. 같은 인덱스를 써도 왜 느릴 수 있을까
여기서부터는 9편(커버링 인덱스)의 직접 응용입니다.
### 상황 설정
`my_table`에 `idx_a_date(a, date_column)` 인덱스가 있습니다. 다음 두 쿼리를 비교해봅시다.
**쿼리 ①: 인덱스 컬럼만으로 답이 나오는 경우**
```sql
SELECT date_column, COUNT(*)
FROM my_table
WHERE a = 1
GROUP BY date_column;
```
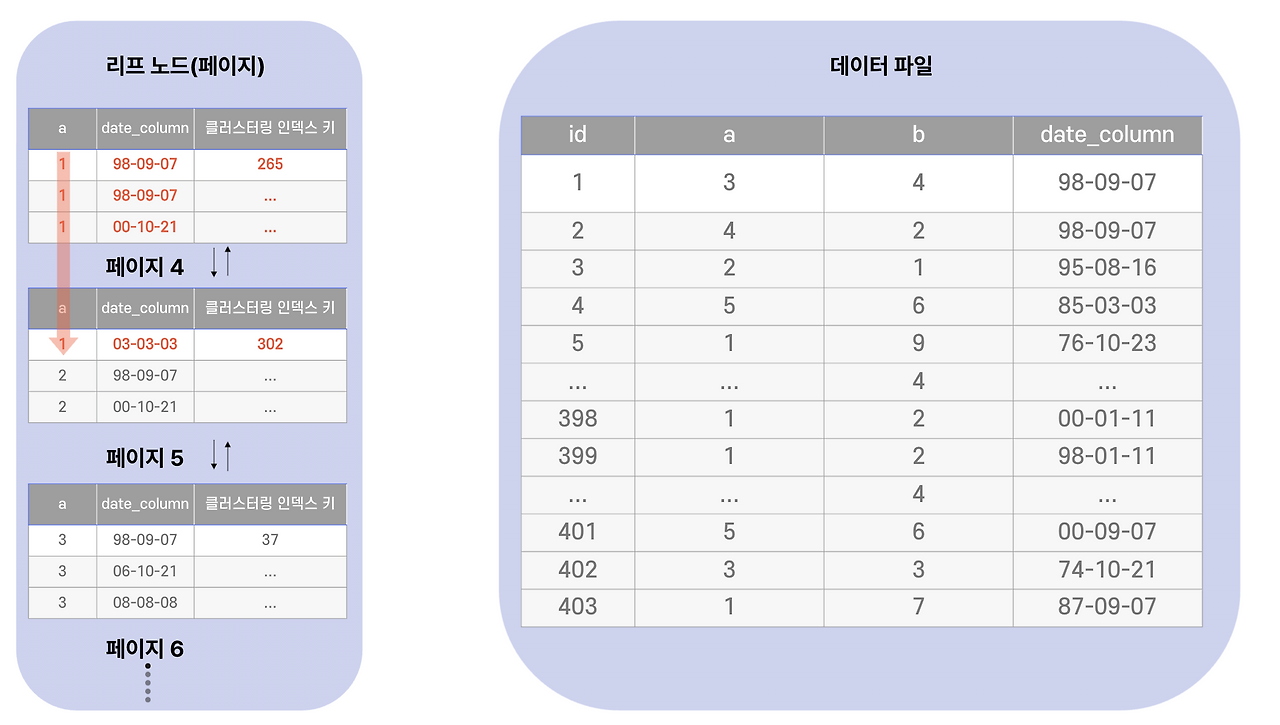
`a = 1`로 인덱스 범위를 좁힌 뒤, `date_column`별로 묶어 개수를 세면 끝. **인덱스만 훑고 끝납니다.**
EXPLAIN 결과:
| id | type | key | rows | filtered | Extra |
|---|---|---|---|---|---|
| 1 | ref | idx_a_date | 989 | 100 | **Using index** |
**`Using index`** — 9편에서 본 그것, **커버링 인덱스**가 적용됐다는 신호입니다. `filtered`가 100%인 것도 주목하세요. 인덱스로 거른 행이 곧 답이라는 뜻입니다.
**쿼리 ②: 인덱스에 없는 컬럼이 조건에 끼는 경우**
```sql
SELECT date_column, COUNT(*)
FROM my_table
WHERE a = 1
AND b = 1 -- ← b는 인덱스에 없음
GROUP BY date_column;
```
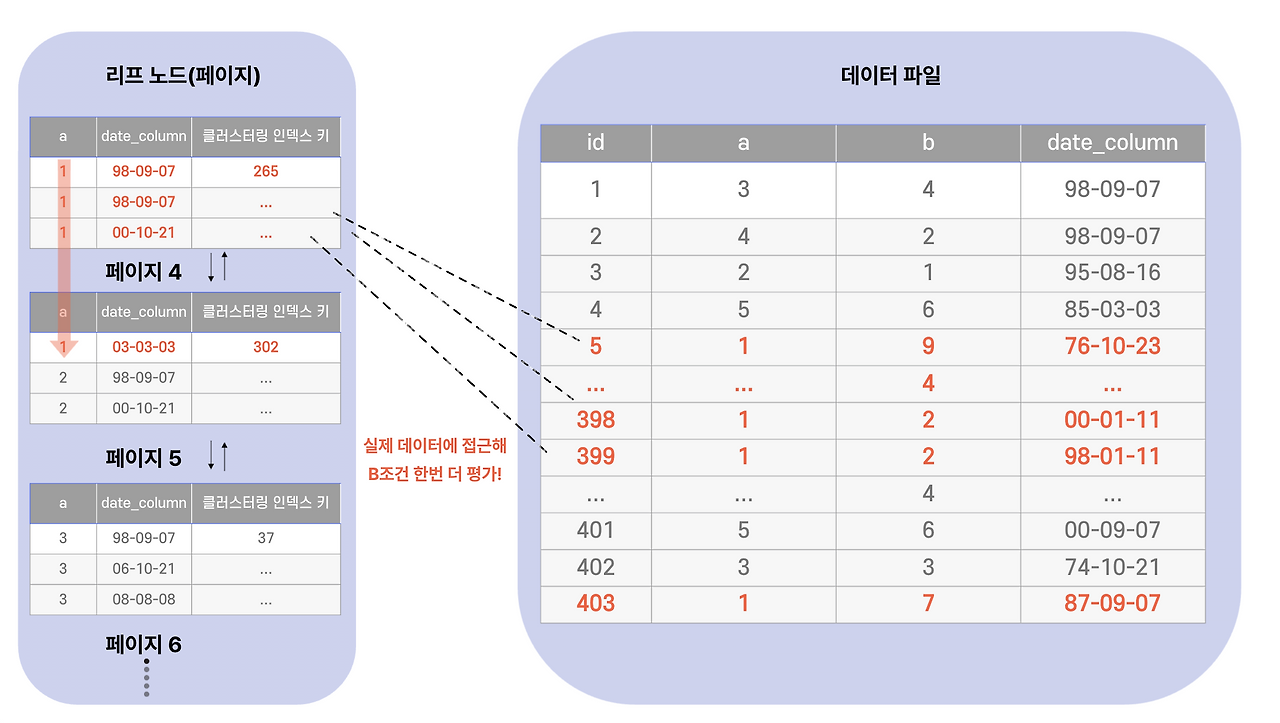
`b` 컬럼은 인덱스에 없습니다. 그래서:
1. `a = 1`로 인덱스를 좁히고
2. **그 결과의 PK로 클러스터링 인덱스에 다시 다녀와서**
3. `b = 1` 조건을 한 번 더 검사
EXPLAIN 결과:
| id | type | key | rows | filtered | Extra |
|---|---|---|---|---|---|
| 1 | ref | idx_a_date | 989 | 10 | **Using where** |
`Extra`가 `Using where`로 바뀌었습니다. `filtered`도 10%로 떨어졌습니다. 인덱스로 추린 989개 중 10%만 실제 답이고, 나머지 90%는 "테이블까지 다녀와서 검사했더니 헛수고였다"는 뜻입니다.
> ⚠️ **헷갈리지 말 것 (9편 복습)**
> - `Using index` = 커버링 인덱스 (좋음, 사전만 보고 끝)
> - `Using where` = 인덱스로 좁힌 뒤 테이블에서 추가 필터링 (커버링 아님)
> - `Using index condition` = Index Condition Pushdown (또 다른 개념)
>
> 셋 다 인덱스를 쓰지만, **테이블에 다녀오는지 여부가 갈립니다.**
### 사전 비유로 다시 보면
쿼리 ①은 사전에 적힌 정보만으로 답이 나오니 책장에 갈 필요가 없습니다. 쿼리 ②는 사전에 적혀 있지 않은 정보(`b`)가 필요해서, 사전에서 위치만 확인하고 **책장까지 직접 가서 책을 펴봐야** 합니다. 책 한 권 가는 건 별일 아니지만, 사전에서 추려낸 책이 1,000권이면 1,000번 책장을 오가야 하죠.
이게 9편에서 다룬 **두 번 탐색의 비용**입니다.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 세 가지:
> 🎯 **PK는 짧게** — 보조 인덱스 N개가 다 같이 뚱뚱해지는 걸 막기 위해
> 🎯 **동등 조건은 앞으로, 범위 조건은 뒤로** — 옵티마이저는 rows × filtered가 작은 쪽을 고른다
> 🎯 **쿼리 조건은 가능한 인덱스 안에서 다 해결되도록** — 인덱스에 없는 컬럼이 끼면 `Using where`로 바뀌고 테이블까지 다녀와야 한다
체크리스트:
- [x] PK가 길면 보조 인덱스 전체가 영향을 받는 이유를 설명할 수 있다
- [x] 같은 쿼리에 후보 인덱스가 여럿일 때, 옵티마이저가 무엇을 보고 고르는지 안다
- [ ] EXPLAIN의 `rows`, `filtered`, `Extra`를 읽고 옵티마이저의 판단을 추적할 수 있다
- [ ] `Using index`와 `Using where`의 차이를 9편 내용과 연결해 설명할 수 있다
- [ ] 인덱스를 설계할 때 동등 조건을 앞에, 범위 조건을 뒤에 두는 이유를 안다
> 📝 체크리스트를 다 채울 자신이 있다면? [**인덱스 응용1 퀴즈 도전하기**](quiz.html?set=E)
---
## 이제 퀴즈에 도전하기
이번 편은 응용1 퀴즈의 전반부(복합 인덱스 파트)를 다뤘습니다.
- PK 길이가 보조 인덱스 전체에 미치는 영향
- 옵티마이저는 rows × filtered로 후보 인덱스를 고른다
- `Using index` vs `Using where` — 같은 인덱스, 다른 비용
후반부(루스 인덱스 스캔)는 11편에서 다룹니다.
> 🎯 [**인덱스 응용1 퀴즈 풀어보기**](quiz.html?set=E)
> 막히는 문제가 있다면 해당 섹션으로 돌아와 다시 읽어보세요.
> 특히 **EXPLAIN의 `rows`, `filtered`, `Extra`를 함께 읽는 능력**이 이번 편의 핵심입니다.
---
## 다음 학습자료
응용1의 후반부, **루스 인덱스 스캔**을 다룹니다. GROUP BY와 MIN/MAX 같은 집계 쿼리에서 옵티마이저가 인덱스를 "듬성듬성" 읽는 최적화입니다.
---
## Reference
- MySQL 공식 문서: [InnoDB Index Types](https://dev.mysql.com/doc/refman/8.4/en/innodb-index-types.html)
- MySQL 공식 문서: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/8.4/en/explain-output.html)
- 참고 글: [복합 인덱스의 컬럼 순서 (jojoldu)](https://jojoldu.tistory.com/565)