#12. 인덱스 스킵 스캔
선두 컬럼 없이도 인덱스를 타는 법
# 인덱스 스킵 스캔 — 선두 컬럼 없이도 인덱스를 타는 법
> 📘 **학습자료 13편** | 연결 퀴즈: [**인덱스 응용2 풀러가기**](quiz.html?set=F)
> "복합 인덱스는 선두 컬럼을 조건에 써야 인덱스를 탄다"는 Left-Most 원칙의 **유일한 예외** 입니다.
> MySQL 8.0+ 에서 도입된 **인덱스 스킵 스캔(Index Skip Scan)** 을 알면, 인덱스가 안 탈 줄 알았던 쿼리가 갑자기 인덱스를 타는 경험을 하게 됩니다.
> 📚 **이전 편**: [12편 - 옵티마이저는 왜 인덱스를 버릴까]
> Left-Most 원칙은 활용1 6편에서 다뤘습니다.
> 12편의 "커버링 인덱스가 옵티마이저 판단을 바꾼다"는 통찰이 이번 편의 두 가지 조건 중 하나로 그대로 이어집니다.
## 이 자료를 다 읽으면 알게 되는 것
- **인덱스 스킵 스캔**이 무엇이고, 왜 만들어졌는지
- 스킵 스캔이 적용되는 **두 가지 조건**과 그 의미
- 같은 인덱스라도 어떤 쿼리는 스킵 스캔이 되고 어떤 쿼리는 안 되는 이유
- EXPLAIN에서 `Using index for skip scan`을 식별하는 법
---
## 📑 목차
- [1. Left-Most 원칙의 한계](#1-left-most-원칙의-한계)
- [⭐ 2. 인덱스 스킵 스캔의 동작](#2-인덱스-스킵-스캔의-동작)
- [3. 적용 조건 ① 선두 컬럼의 카디널리티가 낮아야 한다](#3-적용-조건-선두-컬럼의-카디널리티가-낮아야-한다)
- [4. 적용 조건 ② 커버링 인덱스여야 한다](#4-적용-조건-커버링-인덱스여야-한다)
- [5. 정리: 두 조건이 모두 만족돼야 한다](#5-정리-두-조건이-모두-만족돼야-한다)
- [핵심 요약](#핵심-요약)
---
## 1. Left-Most 원칙의 한계
활용1 6편에서 본 **Left-Most 원칙**을 떠올려봅시다.
> 복합 인덱스 `(A, B, C)`는 **A**가 조건에 있어야 인덱스를 탄다.
> `WHERE B = ?`만으로는 인덱스를 못 탄다.
10편의 사전 비유로 보면, 사전이 "성씨 → 이름" 순으로 정렬되어 있는데 성씨를 모르고 이름만으로 찾으려 하면 사전 전체를 뒤져야 한다는 이야기였습니다.
그런데 한 가지 의문이 생깁니다. 만약 성씨가 단 두 개뿐이라면 어떨까요? "김씨" 페이지를 펼쳐서 거기서 이름으로 좁히고, 다시 "이씨" 페이지를 펼쳐서 거기서 이름으로 좁히면, **사전 전체를 뒤지지 않고도 답을 낼 수 있지 않을까요?**
MySQL 8.0이 도입한 **인덱스 스킵 스캔**이 정확히 이 발상입니다.
---
## 2. 인덱스 스킵 스캔의 동작
> ⭐ **이 자료에서 가장 중요한 섹션입니다.**
### 핵심 아이디어
> **선두 컬럼의 가능한 값을 옵티마이저가 직접 채워 넣어 가면서, 인덱스를 여러 번 좁혀 읽는다.**
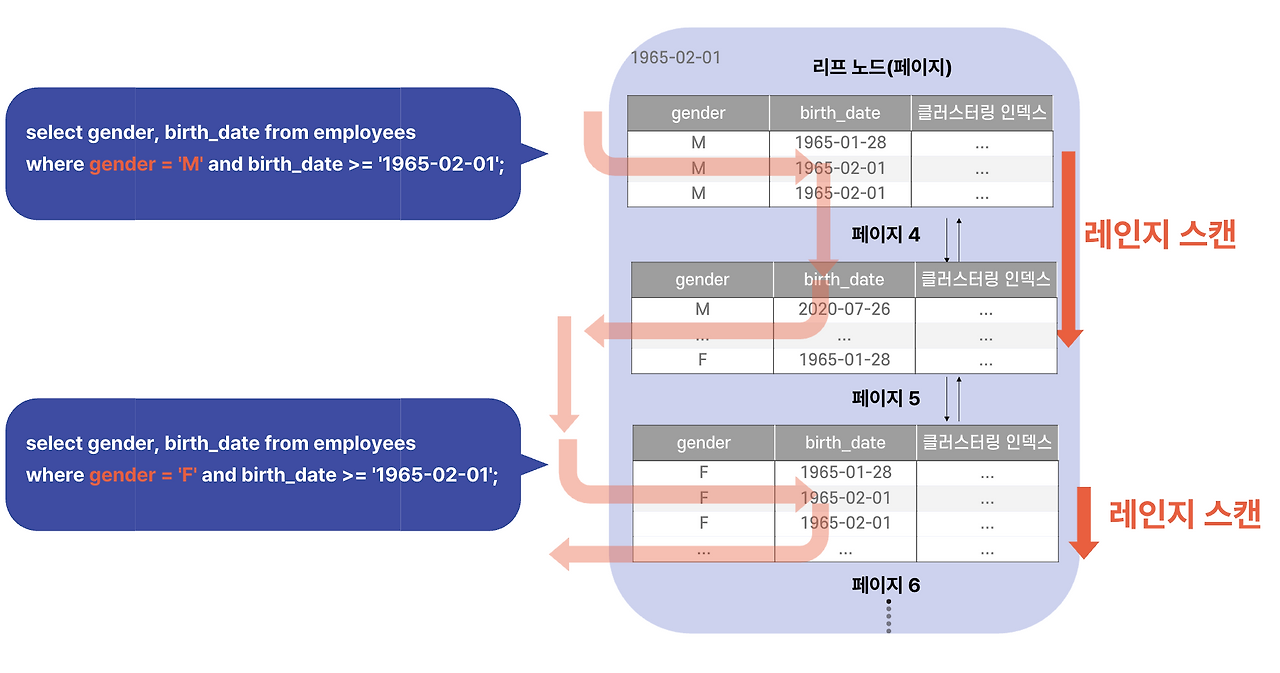
다음 상황을 봅시다.
```sql
-- ix_gender_birthdate (gender, birth_date) 인덱스 존재
SELECT gender, birth_date
FROM employees
WHERE birth_date >= '1965-02-01';
```
`birth_date` 조건만 있고 선두 컬럼인 `gender` 조건이 없습니다. Left-Most 원칙대로라면 인덱스를 못 타야 합니다.
그런데 옵티마이저는 이렇게 생각합니다:
> "`gender`는 `'M'` 아니면 `'F'`잖아? 그럼 내가 직접 두 케이스로 쪼개서 인덱스를 두 번 타면 되겠네."
즉, 마치 다음 두 쿼리를 실행하는 것처럼 동작합니다:
```sql
SELECT gender, birth_date FROM employees
WHERE gender = 'M' AND birth_date >= '1965-02-01';
SELECT gender, birth_date FROM employees
WHERE gender = 'F' AND birth_date >= '1965-02-01';
```
각각은 선두 컬럼 조건이 채워졌으니 인덱스를 정상적으로 활용할 수 있습니다.
### EXPLAIN으로 확인
```sql
EXPLAIN
SELECT gender, birth_date FROM employees
WHERE birth_date >= '1965-02-01';
```
| id | type | key | rows | Extra |
|---|---|---|---|---|
| 1 | range | ix_gender_birthdate | 100,021 | **Using where; Using index for skip scan** |
**`Using index for skip scan`** — 이게 스킵 스캔의 명시적 신호입니다. 11편에서 본 `Using index for group-by`와 비슷한 패턴이죠.
> 💡 **이름의 의미**
> "스킵(skip)"은 인덱스 항목을 건너뛴다는 뜻이 아니라, **선두 컬럼 조건을 건너뛰고도** 인덱스를 활용한다는 뜻입니다.
---
## 3. 적용 조건 ① 선두 컬럼의 카디널리티가 낮아야 한다
스킵 스캔이 항상 좋은 건 아닙니다. **선두 컬럼이 가질 수 있는 값이 너무 많으면 오히려 손해** 입니다.
### 왜 그런가
선두 컬럼 `gender`가 `'M'`, `'F'` 두 개라면 → 인덱스를 **2번** 타면 끝.
만약 선두 컬럼이 LGBTQ까지 포함해 7개로 늘어난다면? 인덱스를 **7번** 타야 합니다. 가능한 값이 100개라면 100번이고요.
```sql
-- 선두 컬럼 값이 7개일 때, 옵티마이저가 펼쳐야 할 쿼리 수
SELECT ... WHERE gender = 'M' AND birth_date >= ...
SELECT ... WHERE gender = 'F' AND birth_date >= ...
SELECT ... WHERE gender = 'L' AND birth_date >= ...
SELECT ... WHERE gender = 'G' AND birth_date >= ...
SELECT ... WHERE gender = 'B' AND birth_date >= ...
SELECT ... WHERE gender = 'T' AND birth_date >= ...
SELECT ... WHERE gender = 'Q' AND birth_date >= ...
```
이 정도가 되면 옵티마이저는 **"차라리 테이블 풀 스캔이 싸겠다"** 라고 판단합니다. 12편에서 본 그 비용 비교가 여기서도 적용되는 거죠.
### 카디널리티의 의미
데이터베이스에서 **카디널리티(cardinality)** 는 컬럼이 가질 수 있는 **고유 값의 개수**를 의미합니다.
| 컬럼 | 예시 | 카디널리티 |
|---|---|---|
| `gender` | M / F | 2 (낮음) |
| `is_deleted` | true / false | 2 (낮음) |
| `status` | 결제대기 / 결제완료 / 배송중 / ... | 5~10 (낮음) |
| `category_id` | 1 ~ 100 | 100 (중간) |
| `email` | 사용자 이메일 | 행 수만큼 (높음) |
스킵 스캔은 **선두 컬럼의 카디널리티가 낮을 때** 효과적입니다. 일반적으로 수십 개 이하 정도면 옵티마이저가 고려할 만합니다.
> ⚠️ **자주 닿지 않는 직관**
> "성별 컬럼은 카디널리티가 너무 낮아서 인덱스를 만들면 별로 효과 없다"는 말, 들어보셨을 겁니다. 일반적으로는 맞습니다.
> 하지만 **복합 인덱스의 선두 컬럼**으로는 오히려 카디널리티가 낮은 게 스킵 스캔에 유리합니다.
> 인덱스 설계 맥락에 따라 같은 특성이 장점도 단점도 됩니다.
---
## 4. 적용 조건 ② 커버링 인덱스여야 한다
이게 12편과 직접 연결되는 두 번째 조건입니다.
### 왜 커버링이 강제되는가
스킵 스캔은 **인덱스를 여러 번** 탑니다. 만약 그 위에 또 **2차 탐색**까지 일어난다면?
- gender 'M' 케이스로 인덱스 탐색 → PK들 → 클러스터링 인덱스로 또 가서 데이터 가져오기
- gender 'F' 케이스로 인덱스 탐색 → PK들 → 클러스터링 인덱스로 또 가서 데이터 가져오기
12편에서 본 **랜덤 I/O 폭증**이 일어납니다. 옵티마이저는 이 비용을 받아들이지 않습니다.
그래서 MySQL은 스킵 스캔에 **"커버링 인덱스인 경우만 적용"** 이라는 제약을 둡니다. 인덱스만으로 답이 나와야 한다는 뜻이죠.
### 깨지는 케이스
```sql
-- ix_gender_birthdate (gender, birth_date) 인덱스 존재
SELECT gender, birth_date, first_name, last_name
FROM employees
WHERE birth_date >= '1965-02-01';
```
`first_name`, `last_name`은 인덱스에 없습니다 → **커버링이 깨짐** → 스킵 스캔 적용 불가.
EXPLAIN 결과:
| id | type | key | rows | Extra |
|---|---|---|---|---|
| 1 | **ALL** | null | 300,094 | Using where |
`type: ALL` — 풀 테이블 스캔. 12편에서 본 그 패턴이 여기서도 똑같이 일어납니다.
---
## 5. 정리: 두 조건이 모두 만족돼야 한다
스킵 스캔의 두 조건을 다시 정리하면:
| 조건 | 의미 | 어겼을 때 |
|---|---|---|
| ① 선두 컬럼의 카디널리티가 낮음 | 인덱스를 N번 타도 N이 작아야 함 | 풀 테이블 스캔이 더 싸짐 |
| ② 커버링 인덱스 | 인덱스만으로 답이 나와야 함 | 2차 탐색의 랜덤 I/O 폭증 |
두 조건은 **둘 다** 만족돼야 합니다. 하나라도 깨지면 옵티마이저는 스킵 스캔을 버리고 풀 테이블 스캔이 효율적이라 판단할 것입니다.
### 실무 관점: 언제 스킵 스캔을 기대할 수 있는가
- 자주 쓰는 복합 인덱스의 **선두 컬럼이 enum-like** 일 때 (성별, 상태값, boolean 등)
- 그 위에서 **두 번째 컬럼 조건**으로 자주 쿼리하는 패턴이 있을 때
- 그 쿼리의 SELECT가 **인덱스 안의 컬럼만** 으로 끝날 때
이 세 박자가 맞으면 Left-Most 원칙을 위반한 쿼리도 인덱스를 탑니다.복합인덱스 설계 시 **선두 컬럼을 카디널리티 낮은 enum-like 컬럼**으로 잡는 패턴이 종종 쓰이는 이유 중 하나가 이것이기도 합니다.
> 💡 **MySQL 8.0 이전에는 어땠나**
> 8.0 이전에는 스킵 스캔이 없었기 때문에, 위 쿼리는 무조건 풀 테이블 스캔이었습니다.
> 5.7에서 운영하던 시스템을 8.0으로 올렸더니 일부 쿼리가 갑자기 빨라졌다면, 스킵 스캔이 적용된 케이스일 가능성이 있습니다.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 한 가지:
> 🎯 **선두 컬럼의 카디널리티가 낮고 커버링 인덱스이면, Left-Most 원칙을 위반해도 인덱스가 탄다**
> MySQL 8.0+의 인덱스 스킵 스캔. EXPLAIN의 `Using index for skip scan`으로 확인할 수 있다.
체크리스트:
- [x] 인덱스 스킵 스캔이 무엇이고, 어떤 발상으로 동작하는지 설명할 수 있다
- [x] EXPLAIN의 `Using index for skip scan`을 읽고 의미를 안다
- [ ] 적용 조건 두 가지(낮은 카디널리티 + 커버링)를 안다
- [ ] 두 조건 중 어느 하나라도 깨지면 풀 테이블 스캔으로 떨어지는 이유를 설명할 수 있다
- [ ] 카디널리티가 같은 컬럼이 단일 인덱스로는 비효율적이지만 복합 인덱스 선두로는 유리할 수 있다는 맥락을 안다
> 📝 체크리스트를 다 채울 자신이 있다면? [**인덱스 응용2 퀴즈 도전하기**](quiz.html?set=F)
---
## 이제 퀴즈에 도전하기
응용2 시리즈를 모두 마쳤습니다. 12편과 13편을 합쳐 응용2 퀴즈에 필요한 개념을 다뤘습니다.
- 보조 인덱스 리프에 PK가 있으니 일부 쿼리도 커버링이 된다 (9편 응용)
- 인덱스에 없는 컬럼이 SELECT에 끼면 옵티마이저는 풀 스캔을 고를 수 있다 (12편)
- 그 이유는 2차 탐색의 랜덤 I/O 비용 (12편)
- MySQL 8.0+의 스킵 스캔: 선두 컬럼 조건 없이도 인덱스 활용 가능 (13편)
- 스킵 스캔의 두 조건: 낮은 카디널리티 + 커버링 인덱스 (13편)
> 🎯 [**인덱스 응용2 퀴즈 풀어보기**](quiz.html?set=F)
> 6문제를 풀면서 EXPLAIN 결과를 직접 해석해보세요.
> 막히는 게 있다면 해당 학습자료의 섹션으로 돌아와 다시 읽어보면 됩니다.
> 응용2의 핵심은 **"인덱스의 존재가 사용을 보장하지 않는다"** 와 **"옵티마이저는 비용을 비교한다"** 입니다.
---
## 다음 학습자료
응용2 시리즈를 마쳤습니다. 인덱스의 구조부터 옵티마이저의 비용 모델까지, 인덱스를 보는 눈이 한 단계 더 깊어졌을 것입니다.
다음 주제는 인덱스를 넘어선 또 다른 응용 — JOIN 최적화, 서브쿼리, 옵티마이저 힌트 등을 다룰 예정입니다.
---
## Reference
- MySQL 공식 문서: [Skip Scan Range Access Method](https://dev.mysql.com/doc/refman/8.4/en/range-optimization.html#range-access-skip-scan)
- MySQL 공식 문서: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/8.4/en/explain-output.html)