#15. 페이지 분할과 단편화
PK 선택의 숨은 비용
# 페이지 분할과 단편화 — PK 선택의 숨은 비용
> 📘 **학습자료 16편** | 연결 퀴즈: [**인덱스 고급2 풀러가기**](quiz.html?set=H)
> "AUTO_INCREMENT 쓰지 말고 UUID 쓰자"는 말, 한 번쯤 들어봤을 겁니다.
> 그런데 InnoDB의 클러스터링 인덱스 구조를 알고 나면, **PK 선택은 단순한 식별자 문제가 아니라 디스크 I/O 성능 문제**라는 사실이 보이기 시작합니다.
> 📚 **이전 편**: [15편 - 인덱스 스킵 스캔]
> 클러스터링 인덱스는 3편에서, B-Tree 자료구조는 2편에서 다뤘습니다.
> 이번 편은 그 두 개념이 만나는 지점 — **B-Tree로 구성된 클러스터링 인덱스에 데이터가 삽입될 때 무슨 일이 일어나는가** — 를 다룹니다.
## 이 자료를 다 읽으면 알게 되는 것
- **페이지(Page)** 가 무엇이고, 왜 고정 크기여야 하는지
- **페이지 분할(Page Split)** 이 언제 일어나고, 왜 비용이 큰지
- **페이지 단편화(Fragmentation)** 가 성능을 어떻게 갉아먹는지
- **페이지 머지(Page Merge)** 의 세 가지 조건
- 왜 **AUTO_INCREMENT가 UUID보다 삽입이 빠른지** (그리고 항상 그런 건 아니라는 점)
---
## 📑 목차
- [1. 페이지(Page)가 뭐길래](#1-페이지page가-뭐길래)
- [⭐ 2. 페이지 분할은 어떻게 일어나는가](#2-페이지-분할은-어떻게-일어나는가)
- [3. 페이지 단편화의 두 가지 비용](#3-페이지-단편화의-두-가지-비용)
- [4. Sequential PK vs Non-Sequential PK](#4-sequential-pk-vs-non-sequential-pk)
- [5. 페이지 머지 — 분할의 반대편](#5-페이지-머지--분할의-반대편)
- [6. 실측: 숫자로 보기](#6-실측-숫자로-보기)
- [핵심 요약](#핵심-요약)
- [이제 퀴즈에 도전하기](#이제-퀴즈에-도전하기)
---
## 1. 페이지(Page)가 뭘까
InnoDB에서 데이터는 **행(row) 단위**가 아니라 **페이지(Page) 단위**로 디스크에 읽고 씁니다. InnoDB의 기본 페이지 크기는 **16KB로 고정**되어 있습니다.
> 💡 **왜 페이지가 고정 크기일까?**
> 디스크 I/O는 비쌉니다. 그래서 OS와 DB는 한 번에 일정 크기씩 읽어서 메모리에 올려둡니다. 크기가 들쭉날쭉하면 관리 비용이 폭발하죠. 그래서 "16KB짜리 박스에 데이터를 차곡차곡 담는다"는 약속을 정해둔 것입니다.
즉, 행 1건만 필요해도 그 행이 들어있는 16KB 페이지 전체를 읽습니다. 반대로 16KB 페이지에 100건이 빽빽하게 들어있으면 한 번의 I/O로 100건을 가져올 수 있고요.
이 단순한 사실이 모든 것의 출발점입니다. **페이지에 데이터를 얼마나 빽빽하게 채우느냐가 성능을 결정합니다.**
---
## 2. 페이지 분할은 어떻게 일어나는가
> ⭐ **이 자료에서 가장 중요한 섹션입니다.**
다음과 같이 데이터 1~7이 page#3에 꽉 찬 상태를 봅시다.
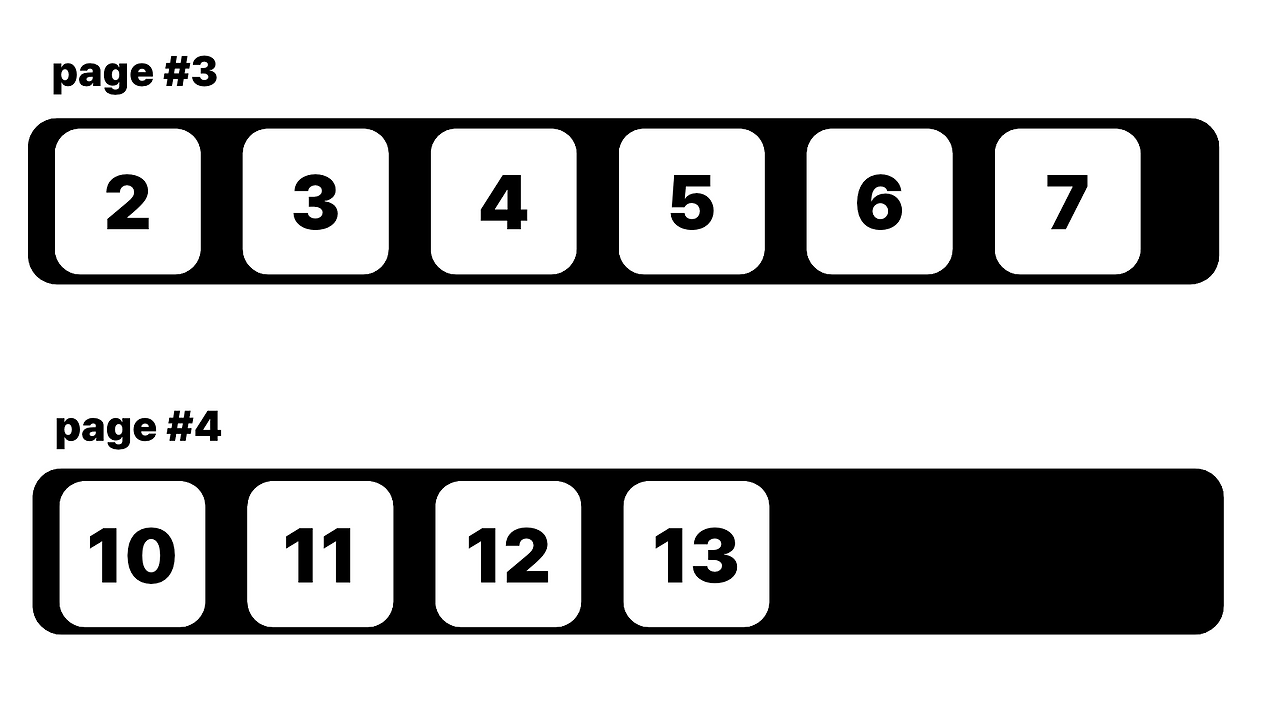
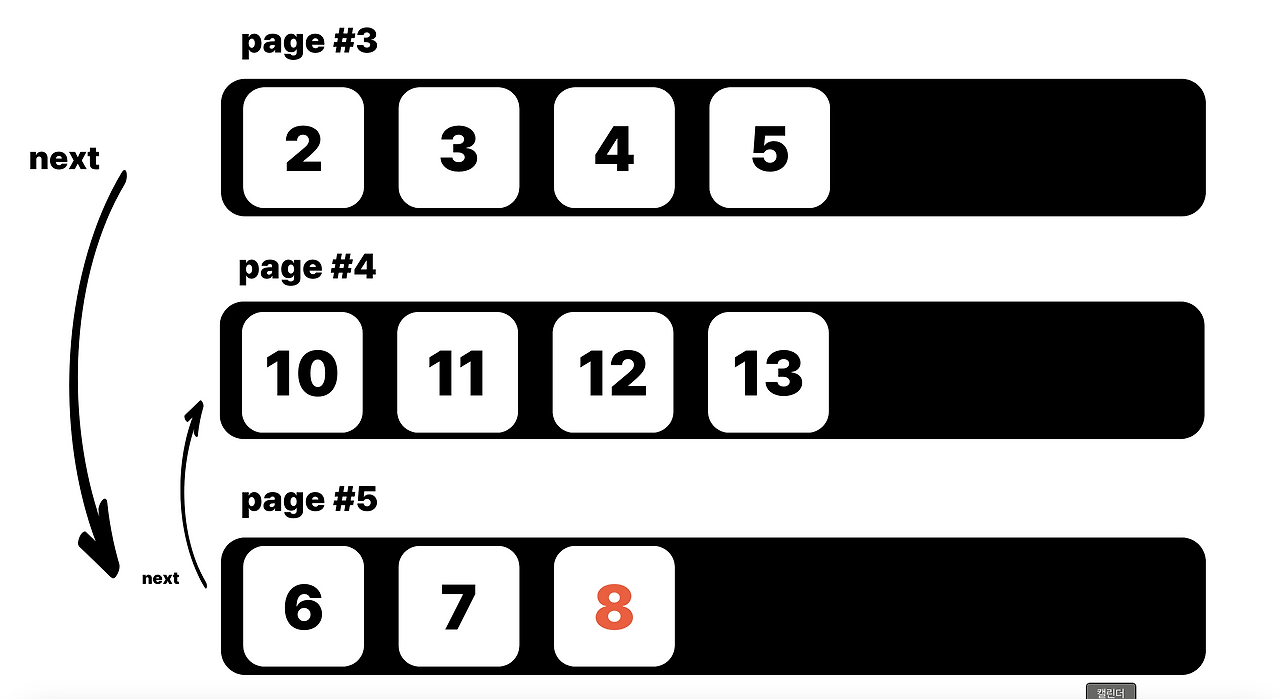
여기에 데이터 8을 삽입하려고 하면 어떻게 될까요? page#3은 이미 꽉 찼고, 페이지 크기는 늘릴 수도 없습니다 (페이지는 고정 크기였으니까요).
InnoDB는 다음과 같이 처리합니다:
1. 새 페이지 page#5를 만든다
2. page#3의 데이터를 **반으로 쪼개서** page#5로 옮긴다
3. 새 데이터 8을 적절한 페이지에 삽입한다
4. **B-Tree의 논리적 순서가 깨지지 않도록** 페이지 간 포인터(다음 페이지 주소)를 다시 연결한다
이 과정 전체를 **페이지 분할(Page Split)** 이라 부릅니다.
> 💡 **왜 굳이 반으로 쪼갤까?**
> 한쪽에 다 몰아두면 그 페이지가 또 금방 꽉 찹니다. 반으로 나눠두면 양쪽 모두 추가 삽입을 받을 여유 공간이 생기죠. 미래의 분할을 줄이려는 트레이드오프입니다.
### 페이지 분할의 비용
언뜻 별일 아닌 것 같지만, 페이지 분할은 다음 작업을 모두 포함합니다:
- 새 페이지 할당 (디스크 공간 확보)
- 데이터 복사 (절반의 데이터 이동)
- B-Tree 포인터 재조정 (이전/다음 페이지 주소 갱신)
- 상위 노드 갱신 (어떤 키 값이 어느 페이지에 있는지 갱신)
단순한 INSERT 한 번에 이 모든 일이 따라온다는 뜻입니다.
---
## 3. 페이지 단편화의 두 가지 비용
페이지 분할이 일어나면 **페이지 단편화(Fragmentation)** 가 발생합니다.
분할 전에는 page#3에 7개의 데이터가 꽉 차있었지만, 분할 후에는 page#3에 4개, page#5에 4개로 **양쪽 모두 절반만 차있는 상태**가 됩니다. 이게 단편화입니다.
단편화가 왜 문제인지, 두 가지 비용으로 나누어 봅시다.
### 비용 ① 공간 낭비
원래 1페이지에 들어가던 7건의 데이터를 이제 2페이지에 나누어 저장합니다. 같은 데이터를 읽으려면 **2번의 페이지 I/O**가 필요해진 거죠. 동일한 데이터인데 디스크 I/O는 배가 된 것입니다.
### 비용 ② Random I/O
원래 page#3 다음에는 page#4가 **물리적으로 인접**해 있었습니다. 디스크는 인접한 영역을 읽을 때(Sequential I/O) 훨씬 빠릅니다.
그런데 page#3과 page#4 사이에 새로 만든 page#5가 **논리적으로** 끼어들었습니다. page#5는 디스크의 다른 위치에 만들어졌기에, 이제 페이지를 읽는 순서는:
```
page#3 → (멀리 떨어진) page#5 → (다시 돌아와서) page#4
```
이렇게 되면 디스크 헤드가 여기저기 점프해야 합니다 (Random I/O). **Sequential I/O 대비 Random I/O는 수십 배 느립니다.**
---
## 4. Sequential PK vs Non-Sequential PK
그럼 본론으로 돌아와서, 왜 PK 선택이 중요할까요?
용어 정리:
> **Sequential PK** : 순차적으로 증가하는 PK (예: AUTO_INCREMENT, Timestamp)
> **Non-Sequential PK** : 순차성이 없는 PK (예: UUID, 랜덤 해시)
InnoDB의 클러스터링 인덱스는 **PK 순서대로 데이터를 정렬해서 저장**합니다. 그러면 두 종류의 PK는 삽입 시 어떻게 다를까요?
### Sequential PK의 경우
새 데이터의 PK는 항상 **기존 데이터보다 큰 값**입니다. 따라서 항상 마지막 페이지의 끝에 추가됩니다.
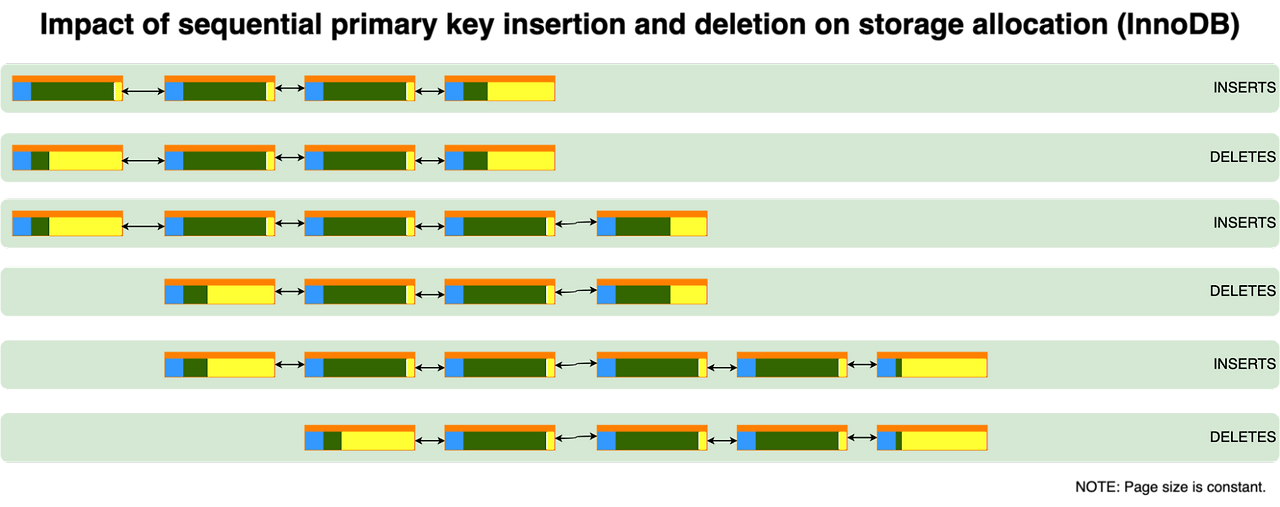
마지막 페이지가 꽉 찼다? 그럼 새 페이지를 하나 만들고 거기에 추가합니다. **이 경우는 페이지 "분할"이 아니라 "추가"입니다.** 기존 페이지를 쪼갤 필요가 없습니다.
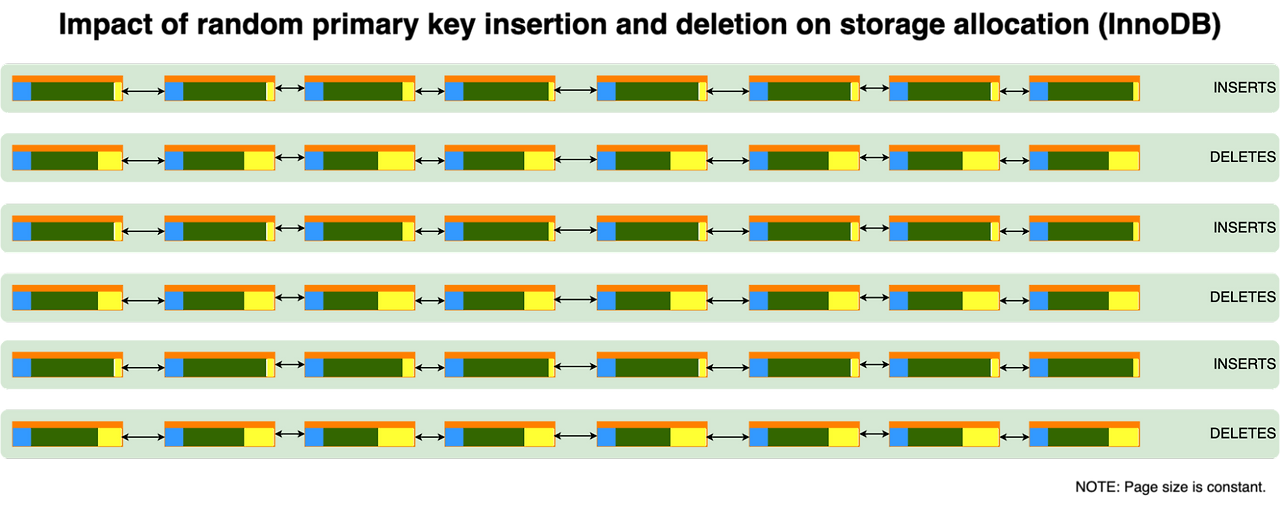
### Non-Sequential PK의 경우
새 데이터의 PK는 **어디로 갈지 예측 불가능**합니다. UUID를 생각해보면 어떤 값은 1번 페이지 중간에, 어떤 값은 500번 페이지 중간에 들어가야 합니다.
그런데 그 페이지가 이미 꽉 차 있다면? **페이지 분할이 일어납니다.**
> 🎯 **핵심 차이**
> Sequential PK는 페이지 분할이 거의 없다. 끝에 추가만 한다.
> Non-Sequential PK는 페이지 분할이 자주 일어난다. 중간 삽입이 많기 때문이다.
> ⚠️ **자주 닿지 않는 직관**
> "UUID는 순서가 없어서 인덱스에 안 좋다"는 말은 들어봤을 겁니다. 하지만 정확히 왜 안 좋은지 물으면 답하기 어렵죠. 그 답이 바로 **페이지 분할 빈도** 입니다. 단순히 "정렬이 안 되어서"가 아니라, **"중간 삽입이 많아 페이지 분할과 단편화가 누적되어서"** 가 정확한 답입니다.
---
## 5. 페이지 머지 — 분할의 반대편
데이터를 삭제하면 어떻게 될까요? 페이지의 데이터가 줄어들면 InnoDB는 그 페이지를 이웃 페이지와 합치려고 시도합니다. 이걸 **페이지 머지(Page Merge)** 라 부릅니다.
페이지 머지는 다음 **세 가지 조건**을 모두 만족할 때 시도됩니다:
| 조건 | 의미 |
|---|---|
| ① fill factor가 임계값(기본 50%) 미만 | 페이지에 데이터가 절반 이하로만 차있어야 함 |
| ② 인접한 두 페이지의 데이터 합이 한 페이지에 들어감 | 합쳐서 16KB를 넘으면 안 됨 |
| ③ 페이지들이 B-Tree에서 인접 | 논리적으로 옆에 있어야 함 |
### 예시로 이해하기
16KB 페이지 두 개가 있다고 합시다.
- **case 1**: 페이지1(9KB) + 페이지2(4KB) = 13KB → 한 페이지(16KB)에 들어감 → **머지 성공**
- **case 2**: 페이지1(13KB) + 페이지2(4KB) = 17KB → 한 페이지를 넘김 → **머지 실패**
머지가 실패하면 페이지는 그대로 단편화된 상태로 남습니다.
### 순차 삭제 vs 랜덤 삭제
여기서도 PK의 종류가 영향을 미칩니다.
**순차 삭제 (AUTO_INCREMENT의 앞부분 일괄 삭제)**:
```
DELETE FROM ai_table WHERE num < 500000;
```
PK 순서가 데이터 순서와 일치하므로, 앞쪽 페이지들이 **연속적으로 완전히 비워집니다.** → 인접 페이지가 모두 비어있으므로 머지 시도가 활발하게 일어납니다.
**랜덤 삭제 (UUID 테이블의 일부 삭제)**:
```
DELETE FROM uuid_table WHERE num < 500000;
```
UUID는 num 컬럼과 무관하게 분포되어 있으므로, 삭제는 **모든 페이지에 골고루 분산** 됩니다. 한 페이지에서 절반쯤 삭제되는 경우가 많아지죠.
> 💡 **헷갈리기 쉬운 포인트**
> "랜덤 삭제는 페이지가 골고루 비니까 머지가 잘 일어나겠다"고 생각할 수 있습니다. 하지만 머지에는 ②번 조건 — 합쳐서 한 페이지에 들어가야 함 — 이 있습니다. 양쪽 모두 50% 차있으면 합치면 100%가 되니 가능하지만, 양쪽이 60%/60%라면 합치는 게 불가능합니다. 결국 **랜덤 삭제는 머지 시도 횟수가 들쭉날쭉합니다.**
---
## 6. 실측: 숫자로 보기
이론만으로는 와닿지 않으니 실제 측정을 봅시다.
### 100만 건 삽입 속도
| PK 종류 | 100만 건 삽입 속도 |
|---|---|
| AUTO_INCREMENT | 5s 788ms |
| UUID | 6s 269ms |
약 500ms 차이. **AUTO_INCREMENT가 더 빠릅니다.**
### 페이지 분할 횟수
`information_schema.innodb_metrics`에서 페이지 분할 카운터를 직접 확인할 수 있습니다.
```sql
SET GLOBAL innodb_monitor_enable = 'module_index';
SELECT name, count
FROM information_schema.innodb_metrics
WHERE name = 'index_page_splits';
```
| PK 종류 | 페이지 분할 횟수 |
|---|---|
| AUTO_INCREMENT | 8,412회 |
| UUID | 8,943회 |
UUID가 약 500회 더 많이 분할되었습니다. 삽입 속도 차이도 결국 이 분할 횟수에서 옵니다.
### 페이지 머지 시도 횟수 (50만 건 일괄 삭제 후)
```sql
SET GLOBAL innodb_monitor_enable = 'index_page%';
SELECT name, count
FROM information_schema.innodb_metrics
WHERE name LIKE 'index_page_merge%';
```
| 시도 회차 | AUTO_INCREMENT | UUID |
|---|---|---|
| 1회 | 254,403 | 183,084 |
| 2회 | 254,403 | 254,489 |
| 3회 | 254,403 | 90,035 |
| **평균** | **254,403** | 175,869 |
**AUTO_INCREMENT는 일관되게 약 25만 회**의 머지 시도를 보입니다. 반면 **UUID는 데이터 분포에 따라 들쭉날쭉**합니다 — 18만, 25만, 9만으로 큰 편차를 보이죠.
> 🎯 이게 **순차 삭제는 결과가 예측 가능하고, 랜덤 삭제는 예측 불가능하다** 는 의미입니다. 실무에서 성능을 보장해야 할 때 이 차이는 중요합니다.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 것들:
> 🎯 **페이지 분할은 InnoDB의 INSERT가 단순히 "데이터 한 줄 추가"가 아닌 이유다**
> 꽉 찬 페이지의 중간에 데이터를 끼워넣어야 하면, 페이지를 쪼개고 B-Tree를 재조정해야 한다.
> 🎯 **Sequential PK는 페이지 분할이 거의 없고, Non-Sequential PK는 페이지 분할이 자주 일어난다**
> 그래서 AUTO_INCREMENT가 UUID보다 삽입이 빠르고 단편화도 적다.
> 🎯 **페이지 머지에는 세 가지 조건이 모두 필요하다**
> fill factor < 50%, 인접 페이지 합이 한 페이지에 들어감, B-Tree 상 인접.
체크리스트:
- [ ] 페이지가 무엇이고 왜 고정 크기인지 설명할 수 있다
- [ ] 페이지 분할이 언제, 어떤 비용으로 일어나는지 안다
- [ ] 페이지 단편화의 두 가지 비용(공간 낭비, Random I/O)을 안다
- [ ] AUTO_INCREMENT와 UUID의 페이지 분할 빈도가 왜 다른지 설명할 수 있다
- [ ] 페이지 머지의 세 가지 조건을 안다
- [ ] 순차 삭제와 랜덤 삭제의 머지 패턴 차이를 설명할 수 있다
> 📝 체크리스트를 다 채울 자신이 있다면? [**인덱스 고급2 퀴즈 도전하기**](quiz.html?set=H)
---
## 이제 퀴즈에 도전하기
이번 편에서 익힌 개념들을 다시 정리하면:
- 페이지는 InnoDB의 I/O 단위 (16KB 고정)
- 꽉 찬 페이지 중간에 삽입하려 하면 페이지 분할이 일어남
- 페이지 분할은 단편화로 이어지고, 단편화는 공간 낭비 + Random I/O 비용을 만듦
- Sequential PK는 끝에 추가만 하므로 분할이 거의 없음
- Non-Sequential PK는 중간 삽입이 많아 분할이 자주 일어남
- 페이지 머지에는 세 가지 조건이 모두 필요
다음 편에서는 **함수 기반 인덱스** — MySQL 8.0이 도입한, 표현식에 인덱스를 거는 신박한 기능 — 를 다룹니다. 신박한 만큼 함정도 있으니 주의해서 봐주세요.
---
## Reference
- MySQL 공식 문서: [Index Page Merge Threshold](https://dev.mysql.com/doc/refman/8.4/en/index-page-merge-threshold.html)
- Percona: [InnoDB Page Merging and Page Splitting](https://www.percona.com/blog/innodb-page-merging-and-page-splitting/)
- Percona: [The Impacts of Fragmentation in MySQL](https://www.percona.com/blog/the-impacts-of-fragmentation-in-mysql/)