#3. 클러스터링 vs 보조 인덱스
보조→클러스터링 흐름 이해하기
# InnoDB의 두 가지 인덱스: 클러스터링 vs 보조
> 📘 **학습자료 3편 / 3편** | 연결 퀴즈: [**인덱스 기초1 풀러가기**](quiz.html?set=A)
> InnoDB의 두 인덱스를 구분하고, **보조 인덱스로 조회할 때 일어나는 두 번 탐색** 현상까지 깊이 있게 다룹니다.
> 📚 **이전 편**: [2편 - 인덱스의 자료구조: Hash vs B+Tree]
> 2편에서는 InnoDB가 왜 B+Tree를 표준으로 쓰는지를 살펴봤습니다.
## 이 자료를 다 읽으면 알게 되는 것
- **클러스터링 인덱스**와 **보조 인덱스**의 차이 (리프 노드에 뭐가 들어있나)
- 보조 인덱스로 `SELECT *` 하면 **왜 두 번 탐색**이 일어나는지
- PK를 안 만들면 InnoDB는 **클러스터링 인덱스를 어떻게 정하는지**
- "클러스터링 인덱스"와 "PK"가 사실 **다른 개념**이라는 점
---
## 📑 목차
- [1. 클러스터링 인덱스: 리프 노드가 곧 데이터](#1-클러스터링-인덱스-리프-노드가-곧-데이터)
- [2. 보조 인덱스: 리프 노드에 클러스터링 키](#2-보조-인덱스-리프-노드에-클러스터링-키)
- [3. 보조 인덱스로 조회하면 두 번 탐색한다⭐](#3-보조-인덱스로-조회하면-두-번-탐색한다)
- [4. PK가 없으면 클러스터링 인덱스는 어떻게 정해지나](#4-pk가-없으면-클러스터링-인덱스는-어떻게-정해지나)
- [핵심 요약](#핵심-요약)
- [이제 퀴즈에 도전하기](#이제-퀴즈에-도전하기)
---
## 1. 클러스터링 인덱스: 리프 노드가 곧 데이터
클러스터링 인덱스는 **리프 노드에 실제 데이터 레코드 자체가 들어있는** 인덱스입니다.
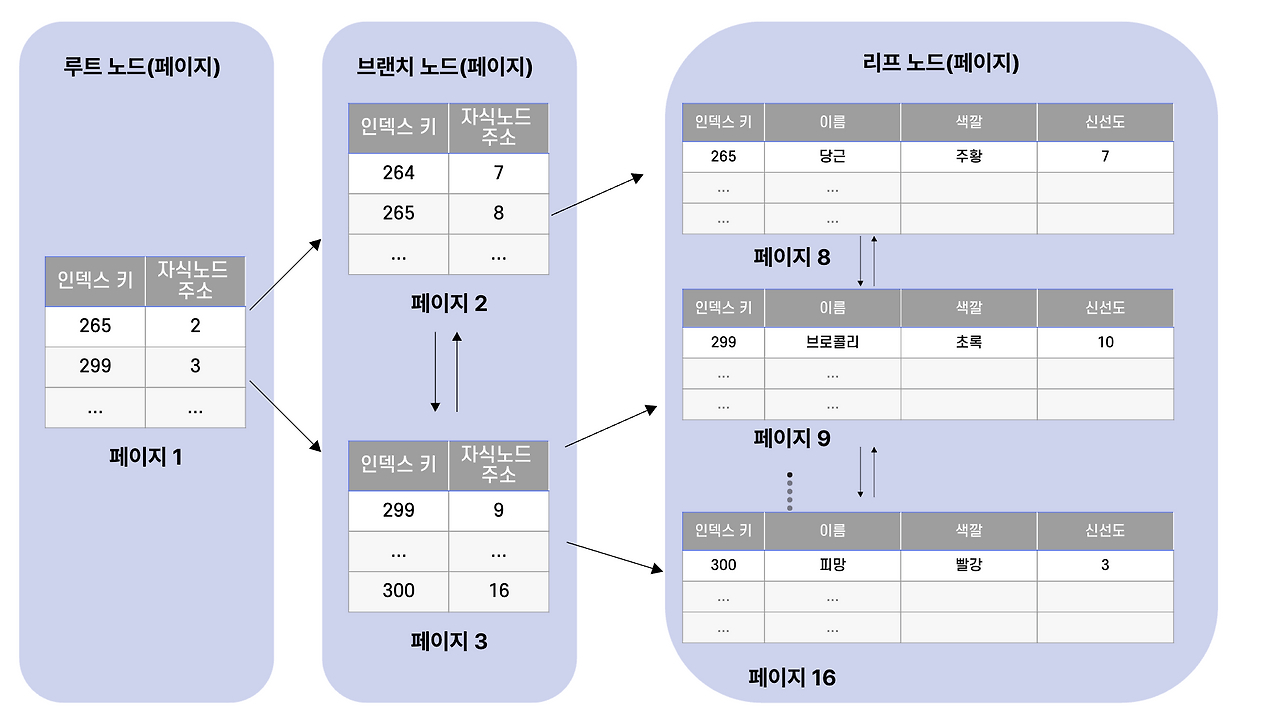
- 루트, 브랜치 노드: 길 안내
- **리프 노드: 인덱스 키 + 그 행의 모든 컬럼 데이터**
즉, 클러스터링 인덱스의 리프 노드까지 도달하면 **추가 작업 없이 모든 데이터를 바로 읽을 수 있습니다.**
**클러스터링 인덱스의 특징 정리:**
- MySQL에서는 **InnoDB 스토리지 엔진에서만 지원**합니다.
- **리프 노드에 실제 데이터 레코드가 저장**되어 있습니다.
- 데이터의 **물리적 저장 순서**를 결정합니다. (클러스터링 인덱스 키 순으로 정렬되어 저장됨)
- **테이블당 단 하나만** 존재할 수 있습니다.
> 💡 **왜 하나만 가능한가?**
> 책을 떠올려보세요. 책은 페이지 순서대로 한 가지 방식으로만 정렬할 수 있습니다. "가나다 순으로 정렬"하면서 동시에 "ABC 순으로 정렬"할 수는 없죠. 클러스터링 인덱스도 마찬가지입니다.
---
## 2. 보조 인덱스: 리프 노드에 클러스터링 키
그러면 클러스터링 인덱스 외에 **추가로 만든 인덱스**(`CREATE INDEX`로 만드는 모든 것)는 어떻게 저장될까요?
```sql
CREATE INDEX idx_email ON users(email);
CREATE INDEX idx_name_age ON users(name, age);
```
Spring Boot + JPA를 쓴다면 이렇게 선언하기도 합니다.
```java
@Entity
@Table(indexes = @Index(name = "idx_email", columnList = "email"))
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String email;
}
```
이렇게 사용자가 추가로 만든 인덱스를 **보조 인덱스(Secondary Index)** 라고 합니다.
보조 인덱스의 B+Tree 구조는 클러스터링 인덱스와 살짝 다릅니다.
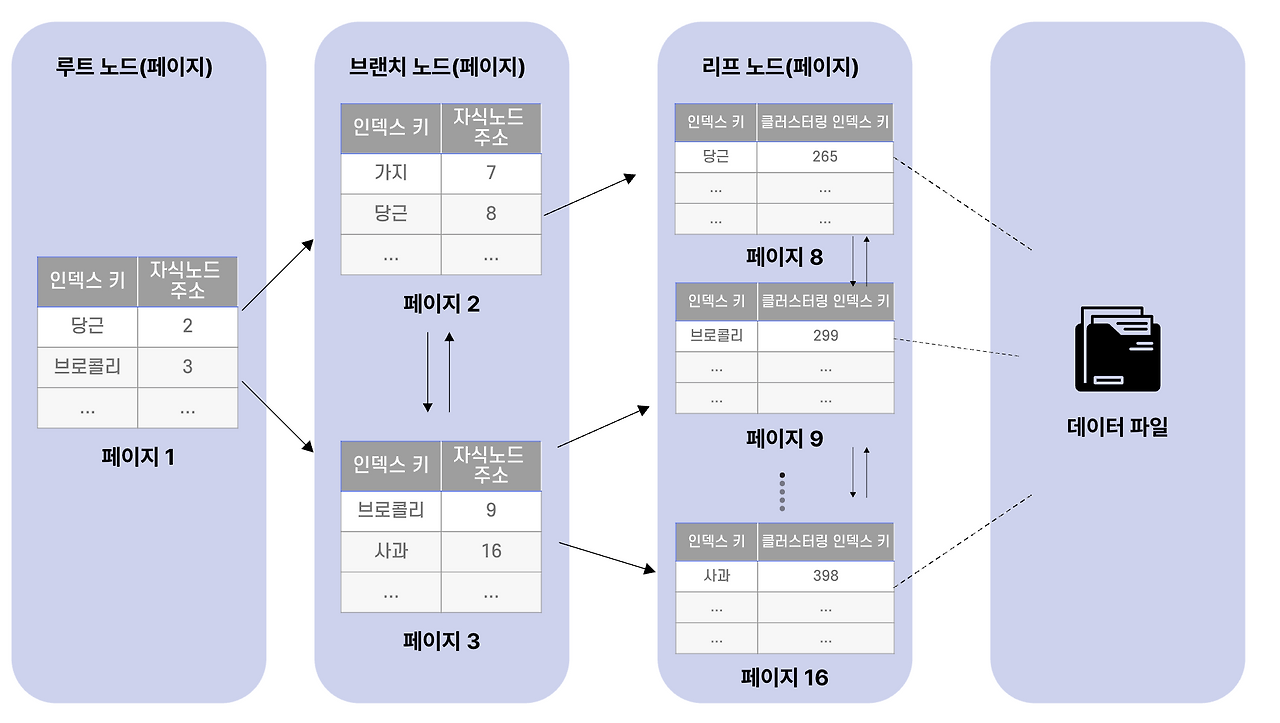
- 루트, 브랜치 노드: 길 안내 (똑같음)
- **리프 노드: 보조 인덱스 키 + 클러스터링 인덱스 키**
여기가 핵심입니다. **보조 인덱스의 리프 노드에는 실제 데이터가 없습니다.** 대신 **"이 행을 찾으려면 클러스터링 인덱스의 어디로 가면 돼"** 라는 안내(클러스터링 키)만 들어있습니다.
> 💡 **왜 실제 데이터가 아니라 클러스터링 키를 저장할까?**
> 만약 보조 인덱스 리프에 실제 데이터를 다 저장한다면, 보조 인덱스를 만들 때마다 데이터가 통째로 복제됩니다. 100개의 보조 인덱스를 만들면 데이터가 100번 복제되겠죠. 비효율적입니다.
> 그래서 보조 인덱스는 **"실제 데이터는 클러스터링 인덱스에 있으니, 거기로 가는 길만 알려준다"** 는 방식을 택합니다.
> 💡 여기까지 이해했다면 이미 퀴즈의 절반은 풀 수 있습니다. [**퀴즈로 확인해보세요!**](quiz.html?set=A)
---
## 3. 보조 인덱스로 조회하면 두 번 탐색한다
> ⭐ **이 자료에서 가장 중요한 섹션입니다.** InnoDB 인덱스 이해의 핵심 포인트이니 천천히 따라오세요.
다음과 같은 상황을 가정해봅시다:
- **클러스터링 인덱스**: PK인 `id` 컬럼 기반
- **보조 인덱스**: `name` 컬럼 기반 (`CREATE INDEX idx_name ON ... (name)`)
- 사용자 쿼리: `SELECT * FROM products WHERE name = '당근'`
이때 InnoDB는 **B+Tree를 두 번 탐색**합니다.
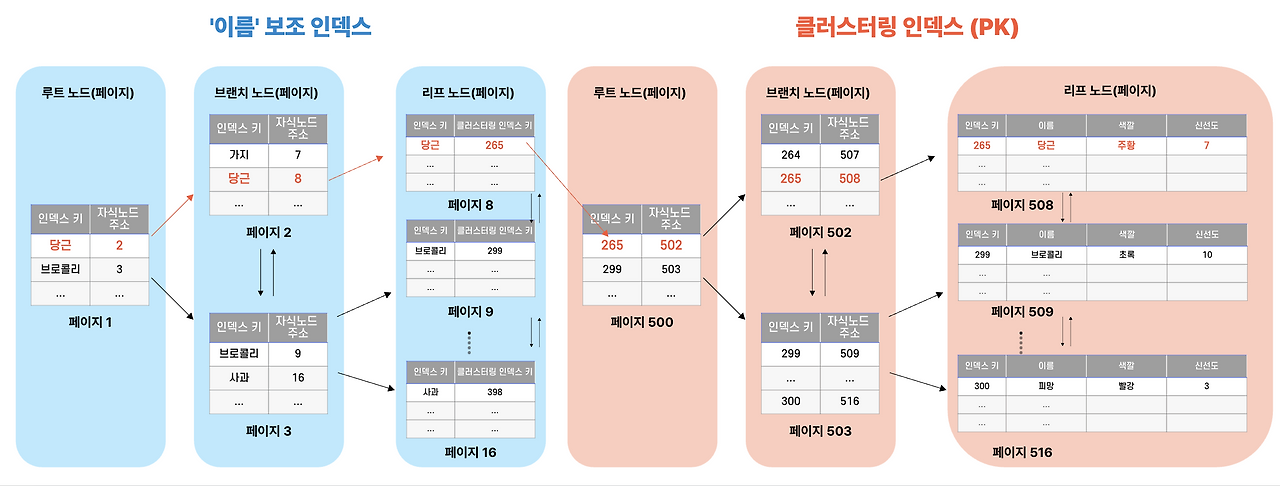
### [1단계] 보조 인덱스 B+Tree 탐색
1. `name` 보조 인덱스의 루트 노드부터 시작
2. 가이드 따라 '당근'이 있는 리프 노드까지 내려감
3. 리프 노드에 도달 → "당근의 클러스터링 키는 **265번**" 이라는 정보를 얻음
여기서 끝이 아닙니다. 우리가 원한 건 `SELECT *` — 행의 **모든 컬럼**입니다. 그런데 보조 인덱스 리프에는 `name`과 `id(=265)`밖에 없습니다. 나머지 컬럼들(가격, 재고, 카테고리...)은 어디 있죠?
### [2단계] 클러스터링 인덱스 B+Tree 재탐색
4. 이번엔 클러스터링 인덱스의 루트 노드부터 다시 시작
5. 가이드 따라 클러스터링 키 **265번**이 있는 리프 노드까지 내려감
6. 리프 노드에 도달 → 거기에 들어있는 **실제 데이터 레코드 전체**를 읽음
**즉, 보조 인덱스로 조회하면 B+Tree 탐색이 두 번 일어납니다.** 한 번은 보조 인덱스에서 클러스터링 키를 알아내기 위해, 또 한 번은 그 클러스터링 키로 실제 데이터를 읽기 위해.
> 💡 **이게 왜 중요한가요?**
> 이 "두 번 탐색" 구조 때문에 InnoDB에서는 다음과 같은 현상들이 일어납니다.
> - **PK가 길면 모든 보조 인덱스가 커진다.** (보조 인덱스 리프마다 PK 값을 들고 있어야 하니까)
> - **보조 인덱스만으로 답을 낼 수 있는 쿼리는 두 번째 탐색이 생략된다.** (이를 "커버링 인덱스"라고 부릅니다)
> - **PK 기반 조회가 보조 인덱스 기반 조회보다 빠른 경우가 많다.** (한 번만 탐색하면 되니까)
이 한 가지 사실만 정확히 이해해도, 인덱스 관련 면접 질문의 절반은 풀립니다.
---
## 4. PK가 없으면 클러스터링 인덱스는 어떻게 정해지나
클러스터링 인덱스는 보통 PK 기준이라고 했는데, **PK를 안 만든 테이블**은 어떻게 될까요?
MySQL 공식 문서에 따르면, InnoDB는 다음 우선순위로 클러스터링 인덱스를 정합니다.
1. 사용자가 명시적으로 지정한 **PRIMARY KEY**
2. **NOT NULL + UNIQUE** 조건을 모두 만족하는 첫 번째 컬럼
3. 그것도 없으면, InnoDB가 내부적으로 **숨겨진 Row ID**를 만들어 사용
**예시로 확인:**
```sql
CREATE TABLE test_case (
col1 INT NOT NULL UNIQUE,
col2 VARCHAR(100)
);
```
이 테이블에는 PK가 없습니다. 하지만 `col1`이 `NOT NULL` + `UNIQUE`이므로 **2순위 규칙에 따라 `col1`이 클러스터링 인덱스 키**가 됩니다.
InnoDB 내부 정보를 확인해봅시다.
```sql
SELECT *
FROM INFORMATION_SCHEMA.INNODB_INDEXES
WHERE NAME = 'col1';
```
| INDEX_ID | NAME | TABLE_ID | TYPE | N_FIELDS | PAGE_NO | SPACE |
|----------|------|----------|------|----------|---------|-------|
| 162 | col1 | 1070 | **3** | 4 | 4 | 4 |
`TYPE = 3`이 **클러스터링 인덱스**를 의미합니다. (각 숫자별 의미는 아래 참고)
<details>
<summary>📎 INNODB_INDEXES의 TYPE 값 의미 (참고)</summary>
```
0 = 일반 보조 인덱스 (nonunique secondary index)
1 = 자동 생성된 클러스터링 인덱스 (GEN_CLUST_INDEX, 위 3순위)
2 = 유니크 보조 인덱스 (unique nonclustered)
3 = 클러스터링 인덱스
32 = 풀텍스트 인덱스
64 = 공간 인덱스
128 = 가상 컬럼 보조 인덱스
```
</details>
> 💡 **주의 — 클러스터링 인덱스 ≠ PRIMARY KEY**
> 위 예시에서 `col1`은 **클러스터링 인덱스로 쓰이지만, PK는 아닙니다.** 둘은 비슷해 보여도 미묘하게 다른 개념입니다.
> - **PK**: 행을 식별하기 위한 논리적 개념. MyISAM 같은 클러스터링을 지원하지 않는 엔진에도 존재.
> - **클러스터링 인덱스**: InnoDB의 물리적 저장 방식. 데이터를 어떤 순서로 디스크에 정렬해 저장할지를 결정.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 한 가지:
> 🎯 **InnoDB의 보조 인덱스로 `SELECT *`를 하면 B+Tree를 두 번 탐색한다**
> 보조 인덱스 → 클러스터링 키 획득 → 클러스터링 인덱스 → 실제 데이터.
> 이 한 문장이 InnoDB 인덱스 면접의 절반을 차지합니다.
체크리스트:
- [x] 클러스터링 인덱스의 **리프 노드에는 실제 데이터**가, 보조 인덱스의 리프 노드에는 **클러스터링 키**가 저장된다
- [x] 클러스터링 인덱스는 테이블당 **하나만** 가능하다
- [ ] 보조 인덱스로 `SELECT *` 하면 **B+Tree를 두 번 탐색**한다
- [ ] PK가 없으면 InnoDB는 **NOT NULL + UNIQUE 컬럼**을 클러스터링 인덱스로 쓰고, 그것도 없으면 숨겨진 Row ID를 만든다
- [ ] 클러스터링 인덱스와 PK는 **서로 다른 개념**이다
---
## 이제 퀴즈에 도전하기
3편에 걸쳐 인덱스의 기초를 모두 다뤘습니다. 이제 학습한 내용을 점검해볼 차례입니다.
- 인덱스가 왜 필요하고 왜 공짜가 아닌지 (1편)
- 왜 B+Tree가 표준이 됐는지 (2편)
- 클러스터링 인덱스와 보조 인덱스의 차이, 두 번 탐색 (3편)
> 🎯 [**인덱스 기초1 퀴즈 풀어보기**](quiz.html?set=A)
> 7문제 중 막히는 게 있다면, 해당 학습자료의 섹션으로 돌아와 다시 읽어보세요. 퀴즈와 학습자료를 오가며 자연스럽게 머릿속에 자리 잡힐 겁니다.
---
## 다음 학습자료
인덱스 기초1을 모두 마쳤습니다. 다음 학습자료에서는 **인덱스 기초2** 주제를 다룹니다.
---
## Reference
- MySQL 공식 문서: [InnoDB Index Types](https://dev.mysql.com/doc/refman/8.4/en/innodb-index-types.html)
- MySQL 공식 문서: [INNODB_INDEXES Table](https://dev.mysql.com/doc/refman/8.4/en/information-schema-innodb-indexes-table.html)