#7. 여러 조건이 결합된 쿼리에서 인덱스
AND/OR/IN
# 여러 조건이 결합된 쿼리에서 인덱스
> 📘 **학습자료 8편 / 9편** | 연결 퀴즈: [**인덱스 활용2 풀러가기**](quiz.html?set=D)
> 단순한 쿼리가 인덱스를 타는 규칙은 활용1에서 봤습니다.
> 이제 더 현실적인 상황 — 함수가 적용되거나, AND/OR/IN으로 여러 조건이 결합된 쿼리에서 인덱스가 어떻게 동작하는지 알아봅니다.
> 📚 **이전 편**: [7편 - 인덱스 레인지 스캔과 Random I/O]
> 7편까지 인덱스의 구조와 단순 조건의 활용을 다뤘다면, 이번 편은 **실무에서 실제로 마주치는 복잡한 쿼리**가 주제입니다.
## 이 자료를 다 읽으면 알게 되는 것
- 함수로 컬럼을 변형한 조건이 **왜 인덱스를 못 타는지**
- 복합 인덱스에서 **AND 조건이 어떻게 인덱스를 활용**하는지
- **OR 조건**이 왜 풀 스캔으로 떨어지는지
- **IN과 NOT IN**의 결정적 차이
---
## 📑 목차
- [1. 함수로 변형된 조건은 인덱스를 못 탄다](#1-함수로-변형된-조건은-인덱스를-못-탄다)
- [2. AND 조건과 복합 인덱스](#2-and-조건과-복합-인덱스)
- [3. OR 조건은 왜 풀 스캔으로 떨어지는가](#3-or-조건은-왜-풀-스캔으로-떨어지는가)
- [4. IN: 동등조건의 OR 합집합](#4-in-동등조건의-or-합집합)
- [5. NOT IN: 인덱스를 포기한다](#5-not-in-인덱스를-포기한다)
- [핵심 요약](#핵심-요약)
---
## 1. 함수로 변형된 조건은 인덱스를 못 탄다
활용1에서 다음 사실을 배웠습니다.
> **인덱스가 일하려면 쿼리가 정렬 순서를 따라가야 한다.**
이 원칙의 가장 자주 발생하는 위반 케이스가 **함수로 컬럼을 변형하는 것**입니다.
### 예시 — 연도로 필터링
날짜 컬럼 `date_column`에 인덱스 `tbl_idx`가 걸려 있다고 합시다. "2024년 데이터만 보고 싶다"는 요구사항을 받습니다.
실수한 쿼리:
```sql
SELECT * FROM tbl WHERE EXTRACT(YEAR FROM date_column) = 2024;
```
직관적으로 깔끔합니다. 그런데 **인덱스를 못 탑니다.**
### 왜 못 탈까?
인덱스는 **원본 데이터**를 정렬해 저장합니다. `tbl_idx`의 리프 노드에는 `2023-12-15`, `2024-01-03`, `2024-08-21`... 같은 **날짜 그대로** 들어있습니다.
그런데 쿼리는 `EXTRACT(YEAR FROM ...)`로 변형된 값을 비교합니다. MySQL 옵티마이저 입장에서는:
> "이 컬럼이 인덱스에 정렬돼 있어도, 먼저 모든 값에 함수를 다 돌려봐야 YEAR 값이 뭔지 알 수 있어."
→ 결국 **모든 행을 다 읽고 계산**해야 하니, 풀 테이블 스캔이 더 효율적이라 판단합니다.
```sql
EXPLAIN SELECT * FROM tbl WHERE EXTRACT(YEAR FROM date_column) = 2024;
```
| id | select_type | table | type | key | rows | Extra |
|----|-------------|-------|------|-----|------|-------|
| 1 | SIMPLE | tbl | **ALL** | null | 16 | Using where |
`type = ALL`, `key = null`. 인덱스 무시됨.
### 해결 — 원본 데이터를 그대로 쓴다
같은 의미의 쿼리를 **함수 없이** 다시 짜봅시다.
```sql
SELECT *
FROM tbl
WHERE date_column >= DATE '2024-01-01'
AND date_column < DATE '2025-01-01';
```
조건의 양변을 보면 컬럼 쪽엔 어떤 변형도 없습니다. 비교 값 쪽만 구체적인 날짜로 정해져 있습니다.
| id | select_type | table | type | key | rows | Extra |
|----|-------------|-------|------|-----|------|-------|
| 1 | SIMPLE | tbl | **range** | tbl_idx | 1 | Using index condition |
`type = range`, `key = tbl_idx`. **인덱스를 활용한 범위 스캔이 일어났습니다.**
> 💡 **자주 보는 안티 패턴들**
> - `WHERE YEAR(created_at) = 2024` → 범위 조건으로
> - `WHERE UPPER(name) = 'KIM'` → 대소문자 정규화는 저장 시점에 (또는 인덱스 시 컬레이션 활용)
> - `WHERE SUBSTRING(code, 1, 3) = 'ABC'` → `WHERE code LIKE 'ABC%'`로 (활용1 6편)
> - `WHERE price * 1.1 > 1000` → `WHERE price > 1000/1.1` (비교 값 쪽으로 연산을 옮기기)
>
> 핵심 원칙: **컬럼은 원본 그대로 두고, 연산은 비교 값 쪽으로 옮긴다.**
---
## 2. AND 조건과 복합 인덱스
이번엔 가장 자주 쓰는 케이스. 여러 조건이 **AND**로 묶인 쿼리입니다.
복합 인덱스 `ix_gender_birthdate (gender, birth_date)`가 있다고 합시다.
```sql
SELECT * FROM employees WHERE gender = 'M' AND birth_date > '1965-02-01';
```
이 쿼리는 **인덱스를 잘 활용합니다.**
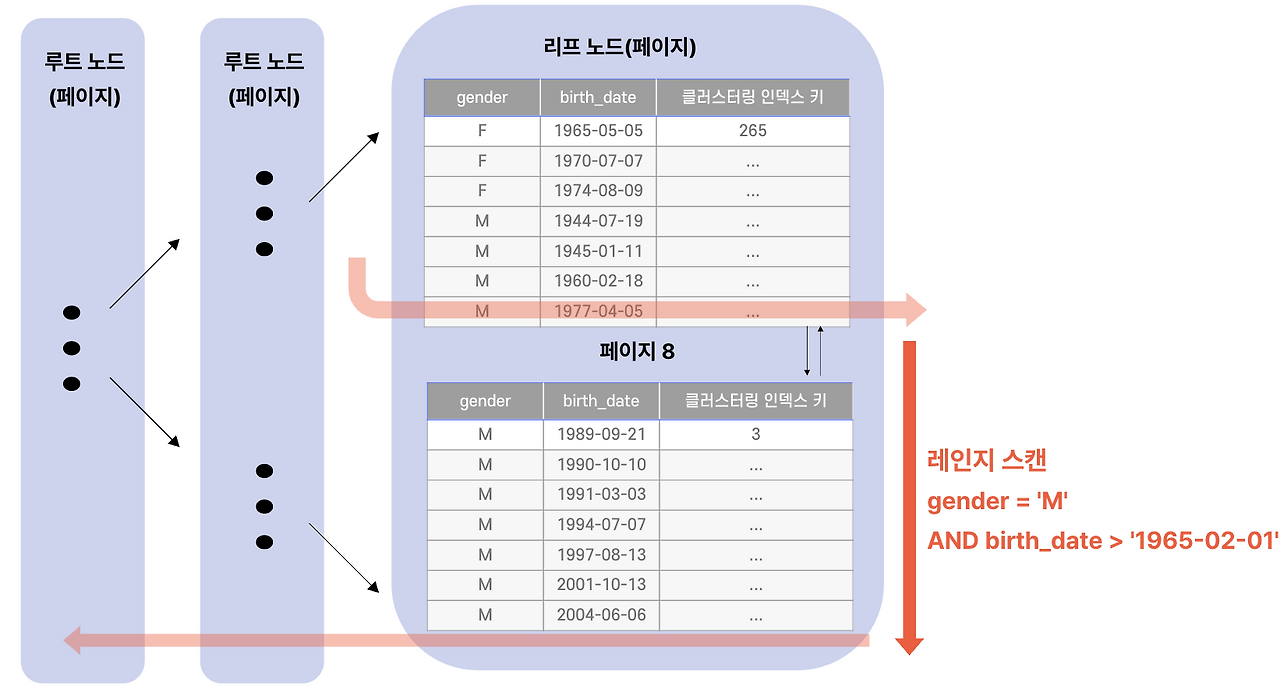
### 동작 원리
복합 인덱스는 **왼쪽 컬럼 우선**으로 정렬되어 있습니다 (활용1 6편의 Left-Most 원칙). `(gender, birth_date)` 인덱스에서:
1. 먼저 `gender = 'M'`인 영역으로 좁힌다 (동등조건)
2. 그 영역 안에서 `birth_date > '1965-02-01'`로 다시 좁힌다 (범위조건)
두 조건이 **모두 인덱스의 정렬 순서를 따르고 있어서** 순차적으로 활용 가능합니다.
> 💡 **복합 인덱스의 일반 규칙**
> `(a, b, c)` 인덱스에서 `WHERE a = X AND b = Y AND c (범위)` 같이 **왼쪽부터 순서대로** 조건이 들어오면 인덱스를 충분히 활용합니다.
> 이 순서가 깨지거나, 중간 컬럼이 빠지면 활용도가 급격히 떨어집니다.
### 함정 — 인덱스를 못 타는 조건과 함께 묶이면?
AND라고 무조건 좋은 건 아닙니다. **인덱스를 활용할 수 없는 조건이 함께 있으면** 어떻게 될까요?
```sql
SELECT * FROM employees
WHERE gender != 'M' AND YEAR(birth_date) > 2000;
```
`gender != 'M'`(비동등조건, 활용1)과 `YEAR(birth_date)`(함수 변형, 위 1번 섹션) — **둘 다 인덱스 활용 불가** 조건입니다.
| id | select_type | table | type | possible_keys | key | rows | Extra |
|----|-------------|-------|------|---------------|-----|------|-------|
| 1 | SIMPLE | employees | **ALL** | idx_gender_birth_date | **null** | 1 | Using where |
`type = ALL`, `key = null`. 풀 스캔입니다.
**핵심**: AND로 묶인다고 해서 그 자체로 인덱스를 타는 게 아닙니다. **각각의 조건이 인덱스 활용 가능한 형태**여야 합니다.
### 또 다른 케이스 — 인덱스에 없는 컬럼이 섞이면?
```sql
SELECT * FROM employees
WHERE gender = 'M'
AND birth_date > '1965-02-01'
AND hire_date > '2000-10-21';
```
`hire_date`는 인덱스 `ix_gender_birthdate`에 없는 컬럼입니다. 옵티마이저는 두 가지 실행 계획을 비교합니다:
1. **풀 스캔 후 모든 조건 검증**: 데이터를 처음부터 끝까지 읽으며 세 조건 모두 검증
2. **인덱스 활용 후 추가 필터링**: 복합 인덱스로 `(gender, birth_date)` 조건 만족하는 행을 좁힌 뒤, `hire_date`만 검증
이 경우 옵티마이저는 보통 **2안을 선택**합니다.
| id | select_type | table | type | key | Extra |
|----|-------------|-------|------|-----|-------|
| 1 | SIMPLE | employees | **range** | idx_gender_birth_date | Using index condition; **Using where** |
`type = range`, `key = idx_gender_birth_date`로 인덱스를 활용했고, `Extra: Using where`로 추가 필터링이 일어났음을 알 수 있습니다.
> 💡 **`Using where`의 의미**
> 인덱스로 1차 필터링 후, **인덱스에 없는 조건**을 추가로 검증할 때 등장합니다.
> 이는 인덱스를 충분히 활용했지만, 모든 조건을 인덱스만으로 해결하지 못했다는 뜻입니다.
> (다음 편의 "커버링 인덱스"에서 이 한계를 넘어섭니다.)
> 💡 여기까지 읽었다면 AND/함수 변형의 인덱스 활용을 충분히 이해한 것입니다. [**퀴즈로 확인해보세요!**](quiz.html?set=D)
---
## 3. OR 조건은 왜 풀 스캔으로 떨어지는가
AND의 형제처럼 보이는 OR. 그런데 동작은 정반대입니다.
```sql
SELECT * FROM employees WHERE gender = 'M' OR birth_date > '1965-02-01';
```
같은 인덱스 `ix_gender_birthdate`가 있어도, 이 쿼리는 **풀 스캔으로 떨어집니다.**
### 왜 못 탈까?
OR의 의미는 **"두 조건 중 하나라도 만족하면 해당"** 입니다.
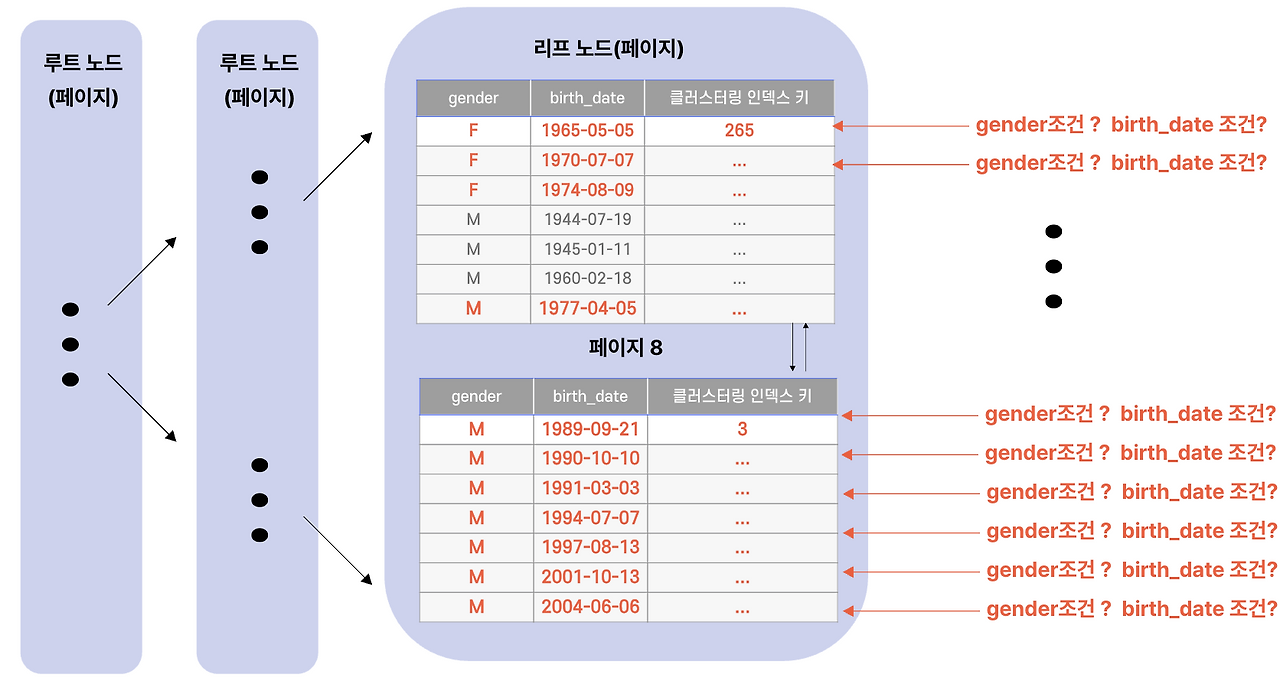
`gender = 'M'`인 행 중에서 `birth_date` 조건을 따지지 않아도 됩니다. 반대도 마찬가지입니다. 결국 **두 조건을 따로따로 검증**해서 합쳐야 합니다.
이걸 인덱스로 풀려면:
1. `gender = 'M'` 조건으로 인덱스 탐색 (X 집합)
2. `birth_date` 조건으로 또 인덱스 탐색 (Y 집합)
3. 두 집합을 합치고 중복 제거
4. 각 행마다 클러스터링 인덱스 재탐색해 실제 데이터 가져오기
이게 풀 스캔(데이터를 한 번 쭉 읽으며 두 조건 다 체크)보다 비싸지면, 옵티마이저는 풀 스캔을 선택합니다. 대부분의 경우 그렇습니다.
```sql
EXPLAIN SELECT * FROM employees
WHERE gender = 'M' OR birth_date > '1965-02-01';
```
| id | select_type | table | type | possible_keys | key | rows | Extra |
|----|-------------|-------|------|---------------|-----|------|-------|
| 1 | SIMPLE | employees | **ALL** | ix_gender_birthdate | **null** | 300094 | Using where |
`possible_keys`엔 인덱스가 보이지만, `key = null`. **옵티마이저가 인덱스를 알지만 안 씀.**
> 💡 **AND vs OR — 한 줄 정리**
> - **AND**: 두 조건을 **모두** 만족 → 인덱스로 좁힐수록 결과 작아짐 → 인덱스 유리
> - **OR**: 두 조건 중 **하나라도** 만족 → 인덱스로 따로 따로 봐야 함 → 인덱스 불리
---
## 4. IN: 동등조건의 OR 합집합
`IN` 절은 OR과 비슷해 보이지만, 동작은 **완전히 다릅니다.**
```sql
SELECT * FROM employees WHERE first_name IN ('Georgi', 'Parto');
```
### IN의 정체
IN은 **동등조건들을 OR로 묶은 것**과 같습니다.
```
first_name IN ('Georgi', 'Parto')
= (first_name = 'Georgi') OR (first_name = 'Parto')
```
3번 섹션에서 OR은 인덱스에 불리하다고 했는데, 왜 IN은 다를까요?
핵심은 **각 조건이 모두 동등조건**이라는 점입니다. 활용1에서 봤듯이 동등조건은 인덱스를 가장 잘 활용할 수 있는 조건입니다 (`type = ref`). 그래서 옵티마이저는:
1. `first_name = 'Georgi'`를 인덱스로 빠르게 탐색
2. `first_name = 'Parto'`를 인덱스로 빠르게 탐색
3. 두 결과를 합집합(union)으로 합쳐 반환
각 단계가 인덱스 동등 탐색이라 매우 빠릅니다.
### 실행계획으로 확인
```sql
EXPLAIN SELECT * FROM employees emp WHERE emp.first_name IN ('Georgi', 'Parto');
```
| id | select_type | table | type | key | rows | Extra |
|----|-------------|-------|------|-----|------|-------|
| 1 | SIMPLE | emp | **range** | ix_firstname | 481 | Using index condition |
`type = range`, `key = ix_firstname`. 인덱스 활용. (참고: `range`로 표시되지만 동작은 여러 동등 탐색의 합집합입니다)
`EXPLAIN ANALYZE`로 더 자세히 보면 실제로 OR로 분리되어 처리됨을 확인할 수 있습니다:
```
-> Index range scan on emp using ix_firstname
over (first_name = 'Georgi') OR (first_name = 'Parto'),
with index condition: (emp.first_name in ('Georgi','Parto'))
```
---
## 5. NOT IN: 인덱스를 포기한다
이제 `IN`의 부정. **`NOT IN`** 입니다. IN과 결과는 정반대인데, 인덱스 동작도 정반대입니다.
```sql
SELECT * FROM employees emp WHERE emp.first_name NOT IN ('Georgi', 'Parto');
```
### 왜 인덱스를 못 탈까?
NOT IN의 의미는 **"이 목록에 없는 모든 행"** 입니다.
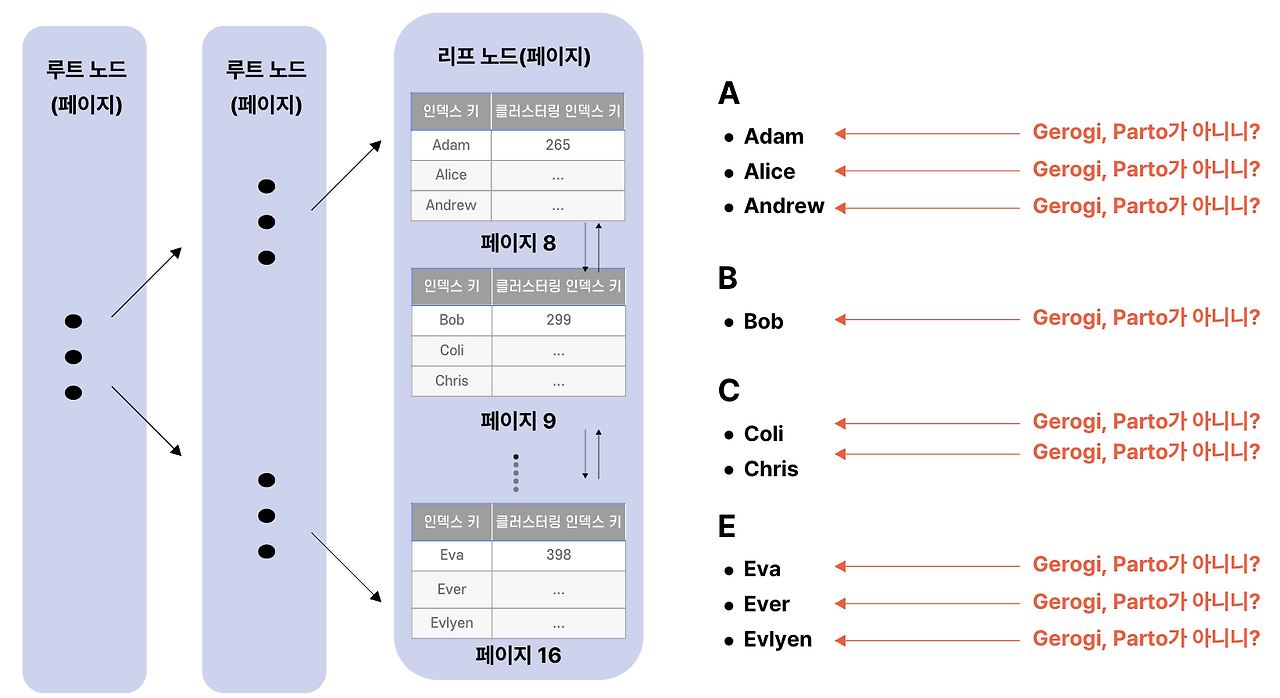
이 조건을 만족하는 행은 **인덱스 곳곳에 흩어져 있습니다.** Georgi와 Parto가 아닌 이름은... 거의 모든 이름입니다. 인덱스의 어느 한 영역으로 좁힐 수 없습니다.
옵티마이저는 두 계획을 비교합니다:
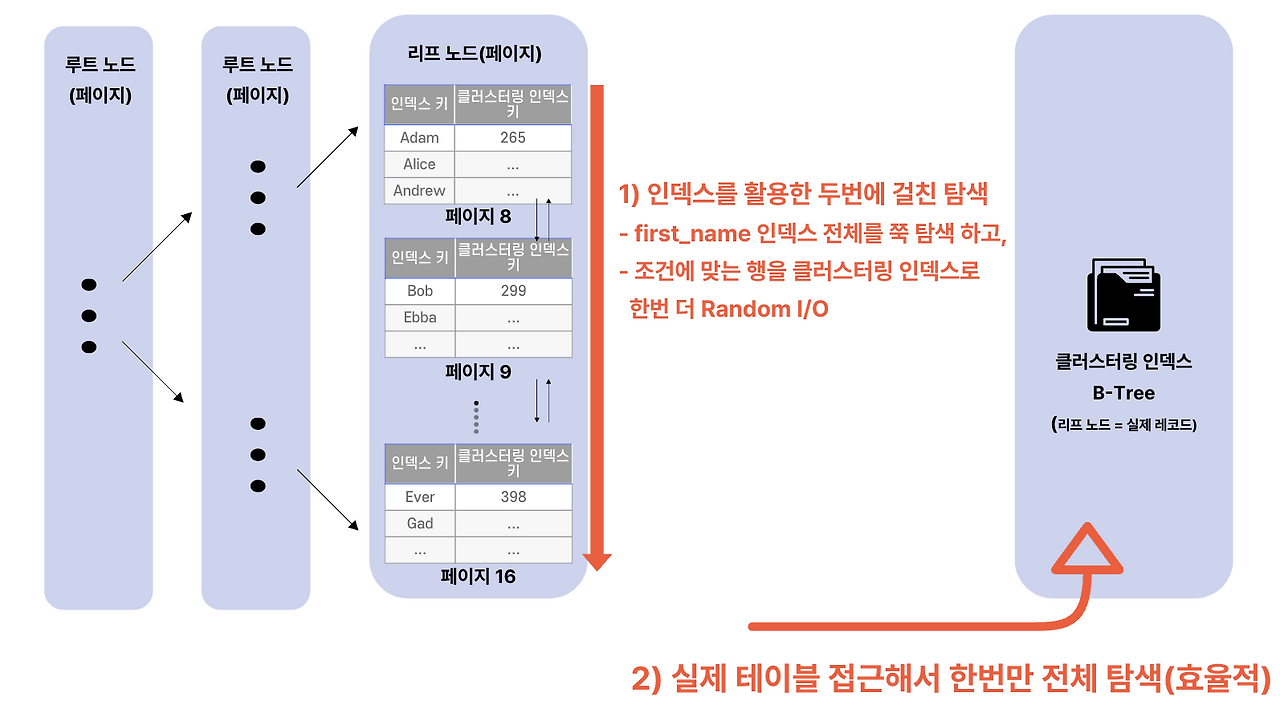
1. **인덱스 활용**: 보조 인덱스 모든 행 탐색하며 NOT IN 검증 → 일치하는 행마다 클러스터링 인덱스 재탐색 (Random I/O 폭증)
2. **풀 스캔**: 데이터를 한 번 쭉 읽으며 NOT IN 검증
거의 항상 **2안이 더 쌉니다.** 그래서 풀 스캔이 주로 활용됩니다.
```sql
EXPLAIN SELECT * FROM employees emp WHERE emp.first_name NOT IN ('Georgi', 'Parto');
```
| id | select_type | table | type | key | rows | Extra |
|----|-------------|-------|------|-----|------|-------|
| 1 | SIMPLE | emp | **ALL** | **null** | 300473 | Using where |
`type = ALL`, `key = null`. 비동등조건(`!=`)과 같은 결과입니다.
> 💡 **IN vs NOT IN — 결정적 차이**
> - `IN`: 인덱스의 **특정 위치들**을 정확히 짚어내면 됨 → 인덱스 유리
> - `NOT IN`: 그 특정 위치들을 **제외한 나머지 전부** → 인덱스 불리
>
> 활용1의 비동등조건(`!=`, `<>`)과 NOT IN은 같은 운명입니다.
> **"무엇이 아닌 것"을 찾는 조건은 인덱스가 작동하지 않는다**고 기억하세요.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 한 가지:
> 🎯 **조건의 결합 방식이 인덱스 활용을 결정한다**
> 같은 인덱스라도 함수가 끼면 무력화되고, AND/OR/IN/NOT IN에 따라 활용도가 천차만별입니다.
> 결국 모든 판단의 기준은 **"이 조건이 인덱스의 정렬 순서를 따라갈 수 있는가"** 입니다.
체크리스트:
- [x] 함수로 컬럼을 변형하면 **왜** 인덱스를 못 타는지 설명할 수 있다 (모든 행에 함수 적용 필요)
- [x] 복합 인덱스에서 AND로 결합된 조건이 인덱스를 활용하는 원리를 안다
- [ ] 인덱스에 **없는 컬럼**이 AND로 섞이면 `Using where`가 등장한다는 것을 안다
- [ ] OR 조건이 풀 스캔으로 떨어지는 이유를 설명할 수 있다 (조건마다 따로 검증 필요)
- [ ] IN과 NOT IN의 동작 차이를 설명할 수 있다 (특정 위치 짚기 vs 나머지 전부)
- [ ] "무엇이 아닌 것"을 찾는 조건들(`!=`, `NOT IN`)은 인덱스 활용이 어렵다는 공통 원리를 안다
> 📝 체크리스트를 다 채울 자신이 있다면? [**인덱스 활용2 퀴즈 도전하기**](quiz.html?set=D)
---
## 다음 편 예고
지금까지 우리는 **"어떤 쿼리가 인덱스를 타는가"** 만 다뤘습니다. 그런데 실은 한 가지가 더 있습니다 — **"무엇을 가져오는가"**.
3편에서 본 것처럼, 보조 인덱스로 `SELECT *` 하면 항상 **두 번 탐색**(보조 인덱스 → 클러스터링 인덱스)이 일어납니다. 그런데 이 두 번째 탐색을 **건너뛸 수 있는** 강력한 카드가 있습니다.
> "인덱스에 이미 필요한 모든 컬럼이 있다면, 굳이 데이터까지 갈 필요가 있을까?"
다음 편의 주제 — **커버링 인덱스(Covering Index)** 입니다. 개발자들이 가장 자주 쓰는 성능 최적화 카드 중 하나이고, 면접에서도 단골로 나옵니다. 그리고 인덱스 **설계** 관점에서 복합 인덱스를 어떻게 짤지에 대한 통찰까지 함께 다룹니다.
---
## Reference
- MySQL 공식 문서: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/8.4/en/explain-output.html)
- MySQL 공식 문서: [Index Condition Pushdown](https://dev.mysql.com/doc/refman/8.4/en/index-condition-pushdown-optimization.html)