#1. 인덱스, 공짜가 아니다
조회↑ 변경↓
# 인덱스, 왜 필요하고 왜 공짜가 아닌가
> 📘 **학습자료 1편 / 3편** | 연결 퀴즈: [**인덱스 기초1 풀러가기**](quiz.html?set=A)
> 인덱스의 가장 기본 개념과, 신입 개발자가 가장 자주 빠지는 함정을 다룹니다.
## 이 자료를 다 읽으면 알게 되는 것
- 인덱스가 **왜 필요한지** (책의 색인 비유)
- 인덱스가 **왜 공짜가 아닌지** (조회 ↔ 변경의 트레이드오프)
- 실제로 **얼마나 빨라지고 얼마나 느려지는지** (벤치마크)
---
## 📑 목차
- [1. 책의 색인 비유](#1-책의-색인-비유)
- [2. 그런데 인덱스는 공짜가 아니다](#2-그런데-인덱스는-공짜가-아니다)
- [3. 실습으로 확인하기](#3-실습으로-확인하기)
- [▶ 핵심 요약](#핵심-요약)
- [▶ 다음 편 예고](#다음-편-예고)
---
## 1. 책의 색인 비유
두꺼운 사전에서 **'가위', '나비', '두꺼비'** 라는 단어를 찾는다고 해봅시다.
색인이 없다면, 책을 한 장 한 장 넘기면서 찾아야 합니다.

하지만 책 뒷부분에 **색인(index)** 이 있다면 이야기가 달라집니다.
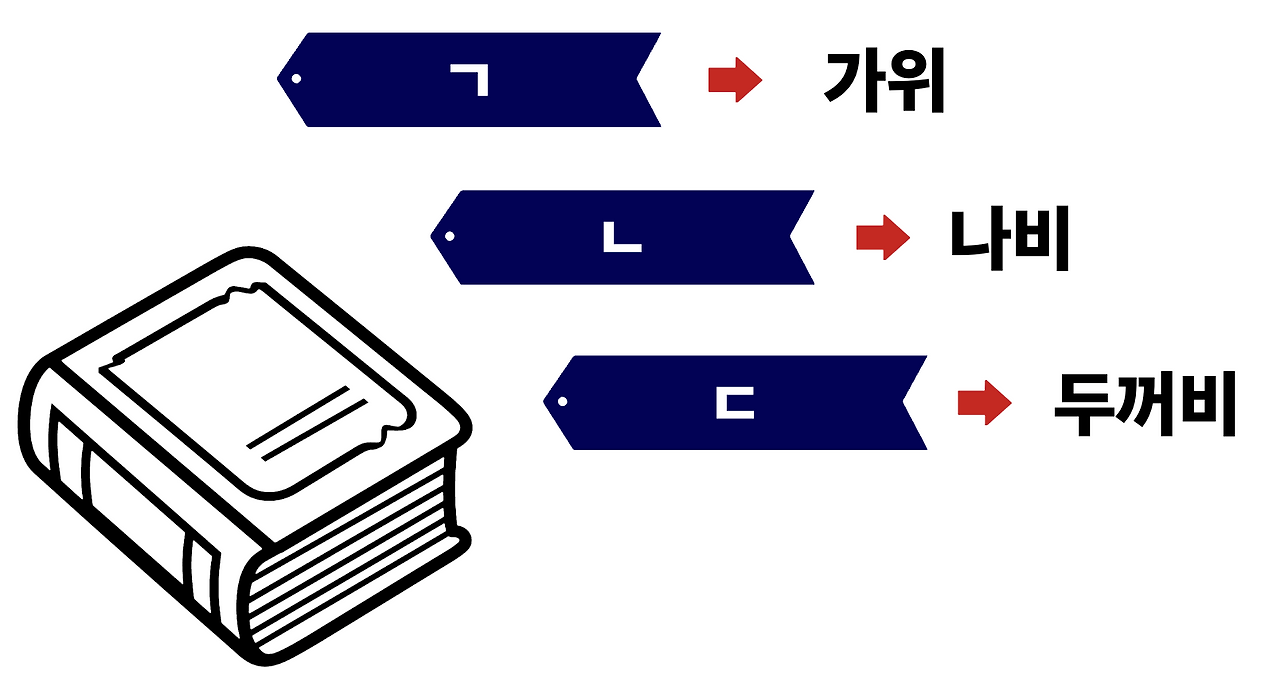
- ㄱ 색인 → '가위' 위치를 바로 안내
- ㄴ 색인 → '나비' 위치를 바로 안내
- ㄷ 색인 → '두꺼비' 위치를 바로 안내
**DB 인덱스도 이것과 똑같습니다.** 데이터베이스에서 원하는 행을 빠르게 찾기 위해 만들어둔 "색인"입니다.
`SELECT * FROM users WHERE name = '홍길동'` 같은 쿼리를 날렸을 때, 인덱스가 있으면 수백만 건 중에서도 '홍길동'을 빠르게 찾아냅니다. 만약 인덱스가 없다면, 1번 행부터 끝까지 다 비교하며 찾아야 합니다. 이를 **풀 스캔(Full Scan)** 이라 부릅니다.
인덱스는 `WHERE` 절의 조건 탐색뿐 아니라 `ORDER BY` 정렬, `JOIN` 등 **조회 성능을 빠르게** 만들어주는 데 폭넓게 쓰입니다.
---
## 2. 그런데 인덱스는 공짜가 아니다
여기서 개발자들이 가장 자주 빠지는 함정이 있습니다.
> "조회가 빨라진다니까, 모든 컬럼에 인덱스를 다 걸어두면 좋은 거 아닌가요?"
**그렇지 않습니다.** 인덱스에는 분명한 **비용**이 있습니다.
새로운 단어 **'라면'** 을 책에 추가한다고 생각해봅시다.
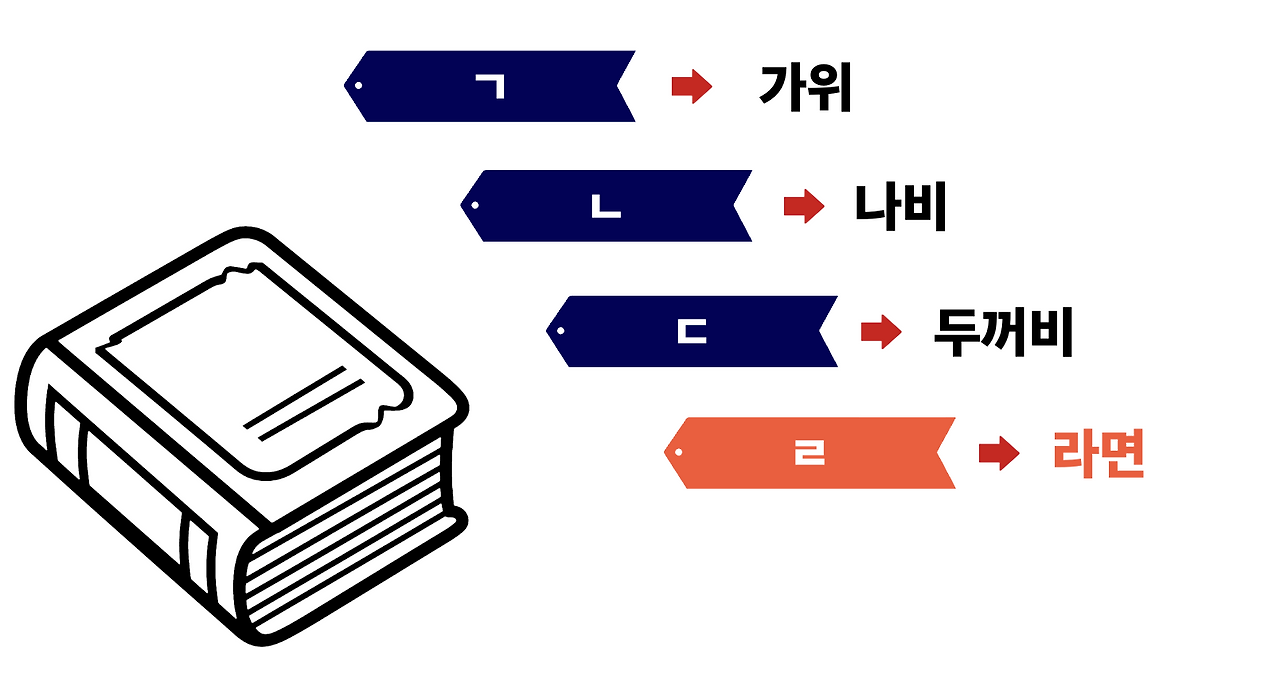
본문에 '라면'을 추가하는 것으로 끝이 아닙니다. **'ㄹ' 색인 페이지에도 '라면'의 위치를 새로 적어둬야** 합니다. 색인 자체도 가나다 순으로 정렬되어 있으니, 'ㄹ' 자리를 찾아 끼워넣는 작업이 필요합니다.
DB도 똑같습니다.
- 데이터를 **삽입(INSERT)** 하면 → 데이터 + 인덱스도 갱신
- 데이터를 **수정(UPDATE)** 하면 → 데이터 + 인덱스도 갱신
- 데이터를 **삭제(DELETE)** 하면 → 데이터 + 인덱스도 삭제
즉, **인덱스가 많을수록 INSERT/UPDATE/DELETE가 느려집니다.**
---
## 3. 실습으로 확인하기
말로만 들으면 와닿지 않으니, 1천만 건 더미 데이터로 직접 비교해보겠습니다.
**삽입 속도 비교:**
| 테이블 | 삽입 쿼리 속도 |
| :----------------------------: | :------------: |
| **no_index_table (인덱스 X)** | **268ms** |
| index_table (인덱스 O) | 626ms |
→ 인덱스 없는 쪽이 **2배 이상 빠릅니다.**
**조회 속도 비교** (`SELECT * FROM 테이블 WHERE name = 'Name12345'`):
| 테이블 | 조회 쿼리 속도 |
| :-------------------------: | :------------: |
| no_index_table (인덱스 X) | 36ms |
| **index_table (인덱스 O)** | **9ms** |
→ 인덱스 있는 쪽이 **4배 빠릅니다.**
> 💡 **핵심 포인트**
> 인덱스는 "조회는 빠르게, 변경은 느리게" 만드는 트레이드오프입니다.
> **조회가 잦은 컬럼에는 인덱스를, 변경이 잦은 테이블에는 인덱스를 신중하게.**
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 한 가지:
> 🎯 **인덱스는 조회 속도를 위해 변경 속도를 희생하는 트레이드오프**
> 무조건 많이 만든다고 좋은 게 아니라, **읽기/쓰기 패턴**을 보고 결정해야 합니다.
체크리스트:
- 인덱스가 **왜 조회를 빠르게** 만드는지 책의 색인 비유로 설명할 수 있다
- 인덱스가 **왜 INSERT/UPDATE/DELETE를 느리게** 만드는지 설명할 수 있다
- "모든 컬럼에 인덱스를 걸자"가 **왜 나쁜 생각**인지 답할 수 있다
---
## 다음 편 예고
이제 우리는 인덱스가 **왜** 필요한지 알았습니다. 그런데 한 가지 의문이 남습니다.
> "DB는 인덱스를 **어떻게** 저장할까? 정렬된 색인을 만든다는 건 알겠는데, 자료구조는 뭐야?"
다음 편에서는 인덱스의 두 가지 후보 자료구조 — **Hash 인덱스**와 **B+Tree 인덱스** — 를 비교하며, 왜 InnoDB가 B+Tree를 표준으로 삼았는지 알아봅니다.
---
## Reference
- MySQL 공식 문서: [How MySQL Uses Indexes](https://dev.mysql.com/doc/refman/8.4/en/mysql-indexes.html)