#11. 커버링 인덱스 심화
옵티마이저는 왜 인덱스를 버릴까
# 옵티마이저는 왜 인덱스를 버릴까 — 커버링 인덱스의 그림자
> 📘 **학습자료 12편 / 13편** | 연결 퀴즈: [**인덱스 응용2 풀러가기**](quiz.html?set=F)
> 9편에서 커버링 인덱스가 **왜 빠른지** 봤다면,
> 이번 편은 **커버링이 깨졌을 때 옵티마이저가 무엇을 선택하는가** 입니다.
> "인덱스가 있는데 왜 풀 테이블 스캔을 하지?" 라는 질문의 답이 여기 있습니다.
> 📚 **이전 편**: [11편 - 루스 인덱스 스캔]
> 9편(커버링 인덱스)을 먼저 읽고 오기를 강력히 권장합니다.
> 이 편은 9편의 **그 다음 이야기** 입니다.
## 이 자료를 다 읽으면 알게 되는 것
- 보조 인덱스의 **2차 탐색 비용**이 풀 테이블 스캔보다 **4~5배 비싸다**는 옵티마이저의 비용 모델
- 그래서 옵티마이저가 **인덱스를 일부러 안 쓰는** 상황
- EXPLAIN에서 `type: ALL`을 만났을 때 무엇을 점검해야 하는지
---
## 📑 목차
- [1. 9편 한 줄 복습](#1-9편-한-줄-복습)
- [⭐ 2. 옵티마이저는 인덱스를 항상 좋아하지 않는다](#2-옵티마이저는-인덱스를-항상-좋아하지-않는다)
- [3. 인덱스 2차 탐색은 풀 테이블 스캔보다 4~5배 비싸다](#3-인덱스-2차-탐색은-풀-테이블-스캔보다-4-5배-비싸다)
- [4. 실전 진단: `type: ALL`을 만났을 때](#4-실전-진단-type-all을-만났을-때)
- [핵심 요약](#핵심-요약)
---
## 1. 9편 한 줄 복습
9편에서 커버링 인덱스의 핵심을 정리했습니다.
> **쿼리가 요구하는 모든 컬럼이 보조 인덱스에 있으면 클러스터링 인덱스 재탐색이 사라진다 → `Using index`**
이번 편은 이 명제의 **반대편**을 봅니다. 보조 인덱스에 필요한 컬럼이 **다 들어있지 않을 때** 옵티마이저는 어떻게 행동할까요?
직관적으로는 "그래도 인덱스로 좁힌 다음 테이블에 다녀오면 되지 않나?" 라고 생각하기 쉽습니다. 그런데 옵티마이저는 종종 **그 길을 버립니다.** 왜 그럴까요?
---
## 2. 옵티마이저는 인덱스를 항상 좋아하지 않는다
> ⭐ **이 자료에서 가장 중요한 섹션입니다.**
다음 상황을 봅시다.
```sql
-- test_table에 idx_name_age (name, age) 인덱스 존재
SELECT *
FROM test_table
WHERE name = '홍길동';
```
`SELECT *`라서 `address`, `phone` 같은 인덱스에 없는 컬럼들도 가져와야 합니다. 즉 **커버링이 안 됩니다.**
이때 옵티마이저가 고려할 수 있는 두 가지 길:
**길 A — 인덱스를 활용하는 경로**
1. `idx_name_age`를 따라 `name = '홍길동'`인 행들의 PK 찾기
2. 각 PK마다 클러스터링 인덱스로 가서 `address`, `phone` 가져오기
3. 결과 반환
**길 B — 인덱스를 무시하고 풀 테이블 스캔**
1. 테이블 전체를 처음부터 끝까지 훑으면서
2. 매 행마다 `name = '홍길동'`인지 검사
3. 일치하는 행만 결과로
상식적으로는 길 A가 빨라 보입니다. 인덱스로 좁혔으니까요. 그런데 **옵티마이저는 종종 길 B를 고릅니다.** EXPLAIN 결과:
| id | type | key | rows | filtered | Extra |
|---|---|---|---|---|---|
| 1 | **ALL** | null | 97,588 | 33.33 | Using where |
`type: ALL` — 인덱스를 안 쓰고 테이블 풀 스캔을 했다는 신호입니다. 인덱스가 멀쩡히 있는데도요.
> ⚠️ **자주 놓치는 지점**
> "인덱스가 있는데 왜 안 타지?" — 옵티마이저가 비용을 비교한 결과 **인덱스를 쓰는 게 더 비싸다고 판단**한 겁니다. 인덱스의 존재가 곧 사용을 의미하지 않습니다.
---
## 3. 인덱스 2차 탐색은 풀 테이블 스캔보다 4~5배 비싸다
왜 옵티마이저가 그렇게 판단할까요? 핵심은 **랜덤 I/O의 비용**입니다.
### 길 A의 진짜 비용
길 A의 2번 단계를 다시 보세요. "각 PK마다 클러스터링 인덱스로 가서…"
`name = '홍길동'`인 행이 1만 개라면 → **클러스터링 인덱스 B+Tree를 1만 번 내려가야** 합니다. 그리고 결정적으로:
- 1만 개의 PK는 디스크에 **흩어져 있습니다**
- 각각의 PK 접근은 **랜덤 I/O**
- 버퍼풀에 없으면 매번 디스크 헤드가 움직여야 함
**랜덤 I/O는 순차 I/O보다 훨씬 비쌉니다.** 디스크 입장에서는 한 자리에서 쭉 읽는 게 가장 빠르고, 여기저기 점프하는 게 가장 느립니다.
### 옵티마이저의 비용 모델
MySQL 옵티마이저는 두 길의 비용을 추정해 비교합니다. 일반적으로:
> **인덱스 2차 탐색 1건의 비용 ≈ 풀 테이블 스캔 4~5건의 비용**
즉, 결과로 나올 행 수가 테이블 전체의 **20~25%를 넘으면** 옵티마이저는 풀 테이블 스캔이 더 싸다고 판단합니다. 한 자리에서 쭉 읽는 게 여기저기 점프하는 것보다 낫다는 것이죠.
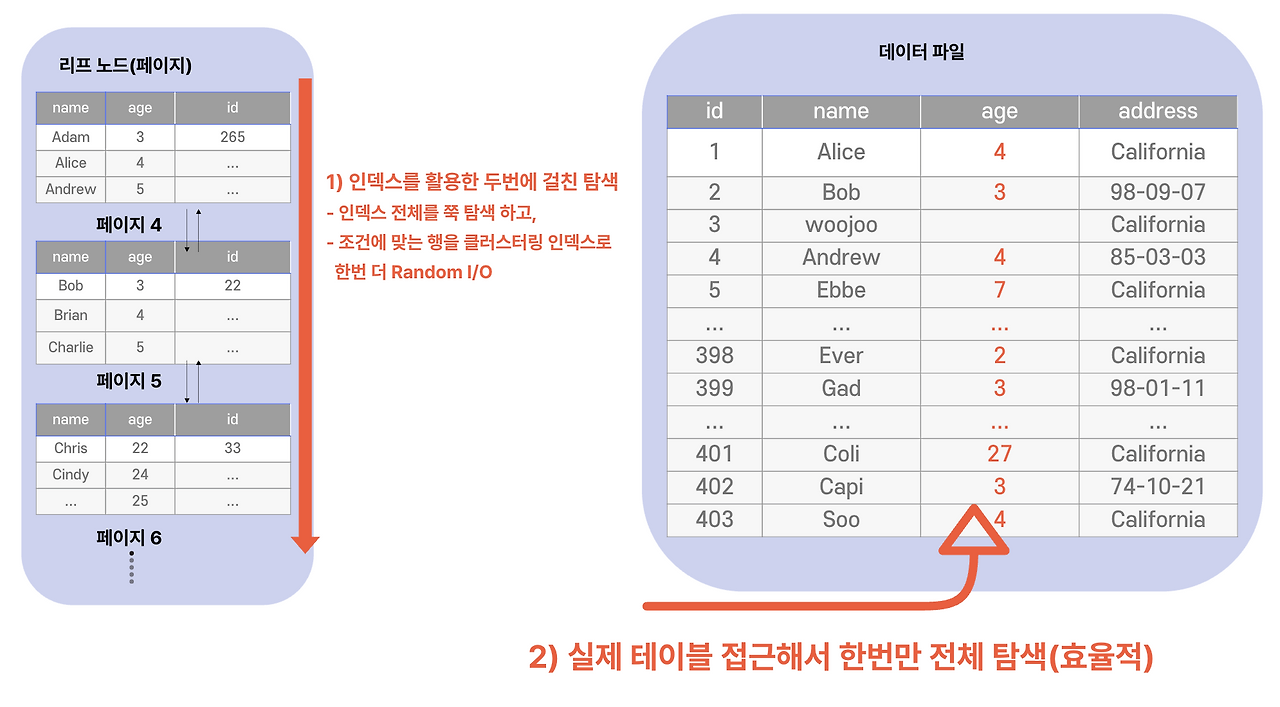
위 예시에서 옵티마이저는:
- `idx_name_age`를 따라 1차 탐색
- 그 결과 PK들로 클러스터링 인덱스 2차 탐색
- 위의 비용을 계산해보니 **테이블을 통째로 한 번 훑는 것보다 4~5배 비싸다**
- → 그래서 인덱스를 버리고 풀 테이블 스캔 선택
> 💡 **9편의 통찰과 연결**
> "커버링 인덱스가 강력한 이유"는 단순히 "한 번 탐색"이라서가 아니라 **랜덤 I/O가 사라지기 때문** 입니다.
> 같은 통찰의 반대 방향이 이번 편의 핵심입니다 — 랜덤 I/O가 너무 많으면 옵티마이저는 인덱스 자체를 포기합니다.
---
## 4. 실전 진단: `type: ALL`을 만났을 때
EXPLAIN을 찍었더니 `type: ALL`이 나왔다면, 다음 순서로 점검하세요.
### 점검 1: 결과가 테이블의 너무 큰 부분을 차지하는가
`SELECT *`로 행이 많이 나올 것 같은 쿼리라면 옵티마이저가 일부러 풀 스캔을 고른 것일 수 있습니다. 이건 **정상 동작** 입니다.
### 점검 2: SELECT 컬럼을 줄일 수 있는가
`SELECT *`를 `SELECT id, name, age` 같은 식으로 줄여서 **커버링 인덱스로 만들 수 있는지** 확인합니다. 커버링이 되면 2차 탐색이 사라지므로 옵티마이저가 인덱스를 다시 선택할 수 있습니다.
### 점검 3: 인덱스를 쿼리에 맞게 새로 짤 수 있는가
자주 쓰이는 쿼리라면 **컴포지트 인덱스에 SELECT 컬럼까지 포함**시켜 커버링으로 만들 수 있습니다.
```sql
-- AS-IS
CREATE INDEX idx_name_age ON test_table(name, age);
-- TO-BE: address까지 포함
CREATE INDEX idx_name_age_addr ON test_table(name, age, address);
```
단, 트레이드오프(인덱스 크기, INSERT/UPDATE 비용)를 같이 고려해야 합니다.
### 점검 4: WHERE 조건이 인덱스를 안 타는 형태인가
함수 변형, OR 조건, 좌측 와일드카드 LIKE 등으로 인덱스를 못 쓰는 경우도 있습니다. 이건 다른 종류의 문제이니 별도 점검이 필요합니다.
---
## 핵심 요약
이번 편에서 꼭 가져가야 할 한 가지:
> 🎯 **옵티마이저는 "인덱스로 좁히기 + 2차 탐색"의 비용이 풀 테이블 스캔보다 비싸다고 판단하면 인덱스를 버린다**
> 인덱스의 존재가 사용을 보장하지 않는다. 커버링 인덱스가 그 비용을 없애는 가장 강력한 카드.
체크리스트:
- [x] 인덱스가 있어도 옵티마이저가 풀 테이블 스캔을 고를 수 있다는 걸 안다
- [x] 그 이유가 **2차 탐색의 랜덤 I/O 비용** 때문임을 설명할 수 있다
- [ ] 일반적으로 인덱스 2차 탐색은 풀 스캔보다 **4~5배 비싸다**는 비용 모델을 안다
- [ ] EXPLAIN에서 `type: ALL`을 만났을 때 점검할 4가지를 안다
- [ ] 커버링 인덱스가 **이 문제를 한 번에 해결**하는 이유를 9편 내용과 연결해 설명할 수 있다
> 📝 체크리스트를 다 채울 자신이 있다면? [**인덱스 응용2 퀴즈 도전하기**](quiz.html?set=F)
---
## 이제 퀴즈에 도전하기
응용2 퀴즈의 전반부(커버링 인덱스 심화)를 다뤘습니다.
- 보조 인덱스 리프에 PK가 있으니 `SELECT id, name, age`도 커버링이 된다
- 인덱스에 없는 컬럼이 SELECT에 끼면 옵티마이저는 풀 스캔을 고를 수 있다
- 그 이유는 2차 탐색의 랜덤 I/O 비용 (12편)
후반부(인덱스 스킵 스캔)는 13편에서 다룹니다.
> 🎯 [**인덱스 응용2 퀴즈 풀어보기**](quiz.html?set=F)
> 막히는 문제가 있다면 해당 섹션으로 돌아와 다시 읽어보세요.
> 이번 편의 핵심은 **"왜 인덱스를 안 쓰지?" 라는 질문에 답할 수 있는가** 입니다.
---
## 다음 학습자료
응용2의 후반부, **인덱스 스킵 스캔**을 다룹니다. MySQL 8.0+에서 도입된 최적화로, **인덱스 선두 컬럼 조건이 없어도** 인덱스를 활용할 수 있게 해주는 기법입니다.
---
## Reference
- MySQL 공식 문서: [How MySQL Uses Indexes](https://dev.mysql.com/doc/refman/8.4/en/mysql-indexes.html)
- MySQL 공식 문서: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/8.4/en/explain-output.html)